The Reality of Scale: What GitHub’s Move to AWS Teaches Us About AI Infrastructure
In the world of high-scale software engineering, we often talk about "scalability" as a theoretical goal. We design for growth, we implement load balancers, and we architect for high availability. However, the recent news that Microsoft is sourcing AWS infrastructure to handle GitHub’s AI demand brings this conversation into a stark, practical reality: sometimes, even the largest cloud providers hit physical limits when faced with the explosive demands of generative AI.
This isn't just a "cloud politics" story; it is a technical warning for every engineering leader building AI-integrated products today. When GitHub’s agentic coding features surged, they didn't just stress test the software—they hit a literal wall in Azure’s available compute capacity. This forced a multi-cloud pivot to ensure that developers using Copilot wouldn't experience downtime.
The "Agentic" Demand and the Compute Wall
The term "agentic coding" refers to AI systems that don't just suggest a single line of code but can perform complex, multi-step tasks—planning, executing, and debugging autonomously. These workflows are computationally expensive. Unlike a standard LLM chat interaction which might be handled by a predictable inference pipeline, agentic workflows often involve recursive loops, multiple tool calls, and high-token throughput in short windows.
When millions of developers hit these features simultaneously, the demand on GPUs is astronomical. Microsoft’s decision to tap into AWS infrastructure highlights a critical truth: Infrastructure is not infinite.
For engineering leaders, this means we can no longer assume that our primary cloud provider has an "infinite" bucket of compute for every new feature we launch. If your product relies on high-inference LLM features, you must account for the physical constraints of the underlying hardware (H100s, A100s, etc.) and the regional availability of those chips.
Architectural Lessons: Moving Beyond Single-Cloud Dependency
The GitHub/Microsoft move is a classic example of why "Multi-Cloud" isn't just a buzzword for enterprise redundancy; it’s becoming a necessity for AI reliability. If your roadmap involves heavy LLM usage, you need to think about how your architecture handles an "inference overflow."
When one region or provider hits capacity limits, does your system have a failover path? A robust strategy involves:
- Abstracting the Provider: Using orchestration layers that allow you to route requests based on availability and latency across different providers (e.g., switching from Azure's OpenAI instance to an AWS Bedrock endpoint if thresholds are met).
- Predictive Scaling: Analyzing usage patterns to pre-provision capacity during known peak times, though this is often insufficient for the "viral" growth seen in AI features.
- Graceful Degradation: If high-compute models (like GPT-4o) hit a limit, can your system automatically fall back to smaller, faster models that have more available headroom?
Engineering Guardrails for Production Readiness
As we move from experimental "proof of concepts" to production-grade AI features, the engineering discipline must tighten. We cannot rely on the cloud provider's infrastructure being "magic." To avoid a crisis when your user base spikes, you need internal guardrails:
1. Version Control and Configuration Drift: Treat your model configurations like code. If you are switching between models or providers to manage capacity, these changes must be versioned. You need to know exactly what configuration was running at any given timestamp to debug why a specific output changed.
- Action: Implement strict CI/CD pipelines for prompt templates and model parameters. Use "diff" tools to ensure that when you switch back from an overflow provider (like AWS) to your primary (Azure), the behavior remains consistent.
2. Observability of Tool-Calls and Trace Logs: In agentic workflows, a single user request might trigger five different tool calls or API hits. If something fails in the chain, "it didn't work" is not an acceptable error message for your team to debug.
- Action: Log every model ID, the specific version of the weights used, and the full trace of tool-calls. This allows you to audit exactly where a failure occurred—was it a logic error in your prompt, or a timeout from the provider?
Building for the Next Wave
The "AI capacity crunch" isn't just an infrastructure problem; it’s a planning problem. When Microsoft had to turn to AWS, it was because they were reacting to a surge that outpaced their immediate local resources.
For startups and mid-market enterprises building AI products today, you don't have the luxury of "reacting" by buying more hardware in real-time. You must build for scale from day one. This means designing your system to be agnostic enough to pivot providers when necessary and robust enough to handle high-volume inference without crashing the user experience.
If you are currently navigating the complexities of scaling AI infrastructure or need help architecting a resilient multi-cloud strategy for your next product launch, let's talk about building an MVP that is actually ready for production. You can reach out for expert guidance here: https://www.nitin-rachabathuni.com/contact.
Summary of Key Takeaways
- Infrastructure Limits are Real: Assume your primary cloud provider will hit capacity limits during high-growth periods for AI features.
- Multi-Cloud is a Strategy, Not an Option: For high-demand LLM applications, having a path to secondary providers (like AWS or GCP) ensures service continuity.
- Auditability is Non-Negotiable: Always log model IDs and tool-call traces to ensure that your results are reproducible and debuggable across different environments.
FAQ
Why did Microsoft turn to AWS for GitHub's user demands? The rapid adoption of "agentic coding" features created a surge in AI inference requests that exceeded Azure's immediate capacity limits. To maintain service availability, Microsoft pivoted to a multi-cloud strategy using AWS infrastructure as an overflow mechanism.
What is the primary technical challenge behind AI capacity crunches? Modern AI features require massive compute overhead for real-time inference across thousands of concurrent users. When demand spikes unexpectedly—as seen with GitHub Copilot's growth—local cloud regions can run out of available GPUs, necessitating a distributed infrastructure approach.
How can engineering teams prepare for similar scaling issues? Teams should implement robust version guardrails to track model configurations, log detailed tool-call traces for auditability, and design architectures that allow for multi-cloud failovers or "fallback" models when primary inference paths hit capacity limits.
Authoritative references
Consult LangGraph.js, MDN Web Docs, web.dev, Next.js documentation, OWASP Cheat Sheets alongside the official references block below. Cross-check guidance with your compliance, security, and SRE stakeholders before setting SLOs.
Metrics snapshot
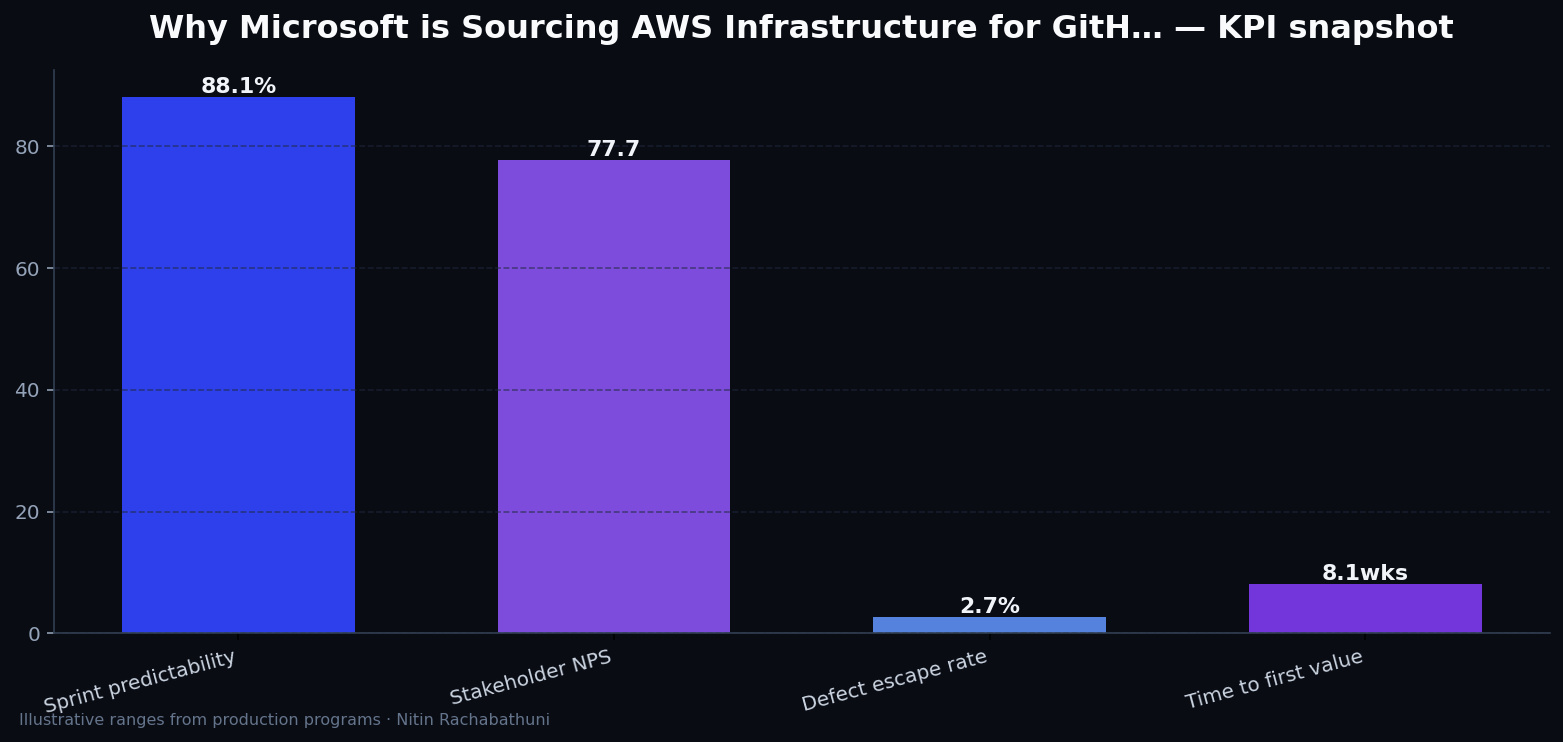
Illustrative consulting KPI ranges observed on programs like “Why Microsoft is Sourcing AWS Infrastructure for GitH…” — validate against your own telemetry before setting SLOs. Methodology: production-like staging traces + weekly review with product and ops.
Architecture flow

Code sketches
/* Integration sketch */
// Why Microsoft is Sourcing AWS Infrastructure for GitH…
export async function rolloutMicrosoftGithubAwsAiCapacityCrunch() {
const checks = ["telemetry", "auth", "rollback"];
return { ok: true, checks };
}
Official references
Related on this site
Related case study
Juiceit.ai — AI platform — document intelligence, agent workflows, enterprise automation.
Article slug: microsoft-github-aws-ai-capacity-crunch · Engineering notes by Nitin Rachabathuni — MVP in 2 days specialist.

Juiceit style straight through document processing
AI Agents
Why Claude Code Switching to a Rust-based Bun Runtime Matters for AI Engineering
tech
Why Anthropic's Move to a Rust-Based Bun Runtime for Claude Code Matters for Engineering Leaders
leadership
Architecting Safety: Why a Dedicated Machine is Essential for Claude Code Agentic Workflows
leadership

LM Studio Bionic: Bridging the Gap Between Chatting and Agentic Workflows
tech

The Zero-Cost Fallacy: Navigating Open Source Risks in the Agentic Era
leadership