Engineering leadership lens — Nitin Rachabathuni connects industry news to production patterns: tradeoffs, observability, and how senior teams evaluate tools before they commit. The notes below translate hype into decision-grade detail. For a direct conversation on scope—audit, implementation, or advisory—use WhatsApp, email, phone, or LinkedIn below. Flexible hourly terms; available across time zones and countries.
Beyond Git: Why Content-Addressed Systems Like Lore are the Future of Scalable Version Control
In the world of software engineering, we often take our primary tools for granted. For over a decade, Git has been the industry standard, providing developers with a reliable way to track changes and collaborate on codebases. However, as infrastructure scales into the thousands of nodes and millions of lines of code, even the most robust systems face friction when balancing local speed against massive-scale integrity.
This is where Lore enters the conversation. Lore isn't just another "Git alternative"; it is a fundamental rethink of how we store and verify data in distributed environments. By moving toward a content-addressed system from the ground up, Lore addresses the architectural bottlenecks that occur when standard version control systems try to stretch across massive scales.
The Architecture of Integrity: Content-Addressed Storage
To understand why Lore is gaining traction among systems architects, we have to look at its foundation: content-addressed storage.
In a traditional file system or some basic version control models, data is often addressed by its location (e.g., /path/to/file). In contrast, content-addressed systems identify data by what it is. Every piece of information—be it a line of code, a configuration file, or an asset—is hashed. If the content changes, the hash changes.
This creates several immediate advantages for large-scale engineering:
- Deduplication: If ten different branches contain the exact same 50MB binary file, a content-addressed system only stores that file once. This drastically reduces storage overhead in massive monorepos.
- Immutability: Because data is identified by its hash, it cannot be changed without changing its address. This creates an immutable history where "what you see is what you get."
- Verification: By using these hashes as the primary identifier, the system can instantly verify that a file hasn't been corrupted or tampered with during transit or storage.
Merkle Trees and Scalable Branching
The core of Lore’s ability to handle scale lies in its use of Merkle trees. A Merkle tree is a hierarchical structure where every leaf node is a hash of data, and every non-leaf node is a hash of its children.
In the context of version control, this means that if you want to compare two massive branches, you don't have to scan every single file. You can simply compare the top-level hashes. If they match, the entire branch below it is identical. If they differ, you move down one level and check those children. This allows for "O(log n)" complexity when identifying differences, which is a game-changer for massive repositories where linear scanning would be prohibitively slow.
By leveraging this structure, Lore ensures that even as the project grows exponentially, the time it takes to verify state or switch branches remains manageable. It moves the heavy lifting from the "human" layer of navigation into the "architectural" layer of data structures.
The Engineering Trade-offs: Performance vs. Complexity
As an engineering leader, I always tell my teams that there is no such thing as a free lunch. To achieve this level of verifiable truth and scalability, Lore adopts a more complex underlying architecture involving languages like C++, Rust, and Go.
Why does this matter? Because to handle the "heavy lifting" of content-addressed storage at scale, you need low-level control over memory management and concurrency. While writing in these languages introduces a steeper learning curve for contributors compared to high-level scripting, it provides the necessary performance primitives to ensure that the system remains fast even when dealing with petabytes of data.
The trade-off here is complexity at the foundation to achieve simplicity at the user interface. The end developer might still just be "checking out a branch," but underneath the hood, a highly optimized engine is ensuring that every byte is accounted for and verified via cryptographic hashes. This is the hallmark of high-level system design: solving hard problems in the infrastructure so they don't become headaches for the end user.
Moving Toward a Verifiable Source of Truth
In modern DevOps environments, "trust" is often implicit—we trust that the build server didn't swap out a dependency; we trust that the production environment matches the staging environment. However, as systems become more distributed and automated, moving toward an explicit source of truth is safer.
By utilizing hash-based storage, Lore creates a system where "truth" isn't just a policy—it’s a mathematical certainty. If the hash doesn't match, the deployment fails. This level of rigor is essential for industries with high security requirements or those managing massive infrastructure footprints where even a minor discrepancy in configuration can lead to catastrophic outages.
If you are currently navigating the complexities of scaling your engineering team and need help building out robust systems that prioritize both speed and integrity, contact me here for MVP consulting to streamline your technical roadmap.
Summary: The Path Forward
The shift toward tools like Lore represents a maturation in how we think about version control. We are moving away from just "tracking changes" and toward "verifying state." By embracing content-addressed storage and Merkle trees, organizations can build systems that are not only scalable but inherently secure.
While the transition to these more complex underlying architectures requires a shift in mindset for some teams, the reward is a system that remains performant as your data grows—ensuring that your infrastructure stays stable, even when your scale becomes massive.
FAQ
What makes Lore different from standard Git workflows? While Git focuses on delta-based changes (tracking what changed between versions), Lore utilizes a content-addressed system built on Merkle trees. This ensures every piece of data is uniquely identified by its hash, providing superior integrity and efficient reuse across massive branches where traditional methods might struggle with scale.
What are the trade-offs of using more complex languages like Rust or Go for version control? These languages offer high performance and memory safety, which are critical for handling large volumes of data efficiently. While they increase initial development complexity compared to higher-level scripts, they provide a much more robust "source of truth" that can handle massive scale without compromising system integrity.
Why is content-addressed storage important for large-scale engineering? Content-addressed storage ensures that identical files are only stored once (deduplication) and provides an immutable record of data. By using Merkle trees, it allows the system to verify huge amounts of data very quickly, making it ideal for massive monorepos or distributed systems where speed and accuracy are both non-negotiable.
Authoritative references
Consult Next.js documentation, MDN Web Docs, web.dev, Next.js documentation, OWASP Cheat Sheets alongside the official references block below. Cross-check guidance with your compliance, security, and SRE stakeholders before setting SLOs.
Metrics snapshot
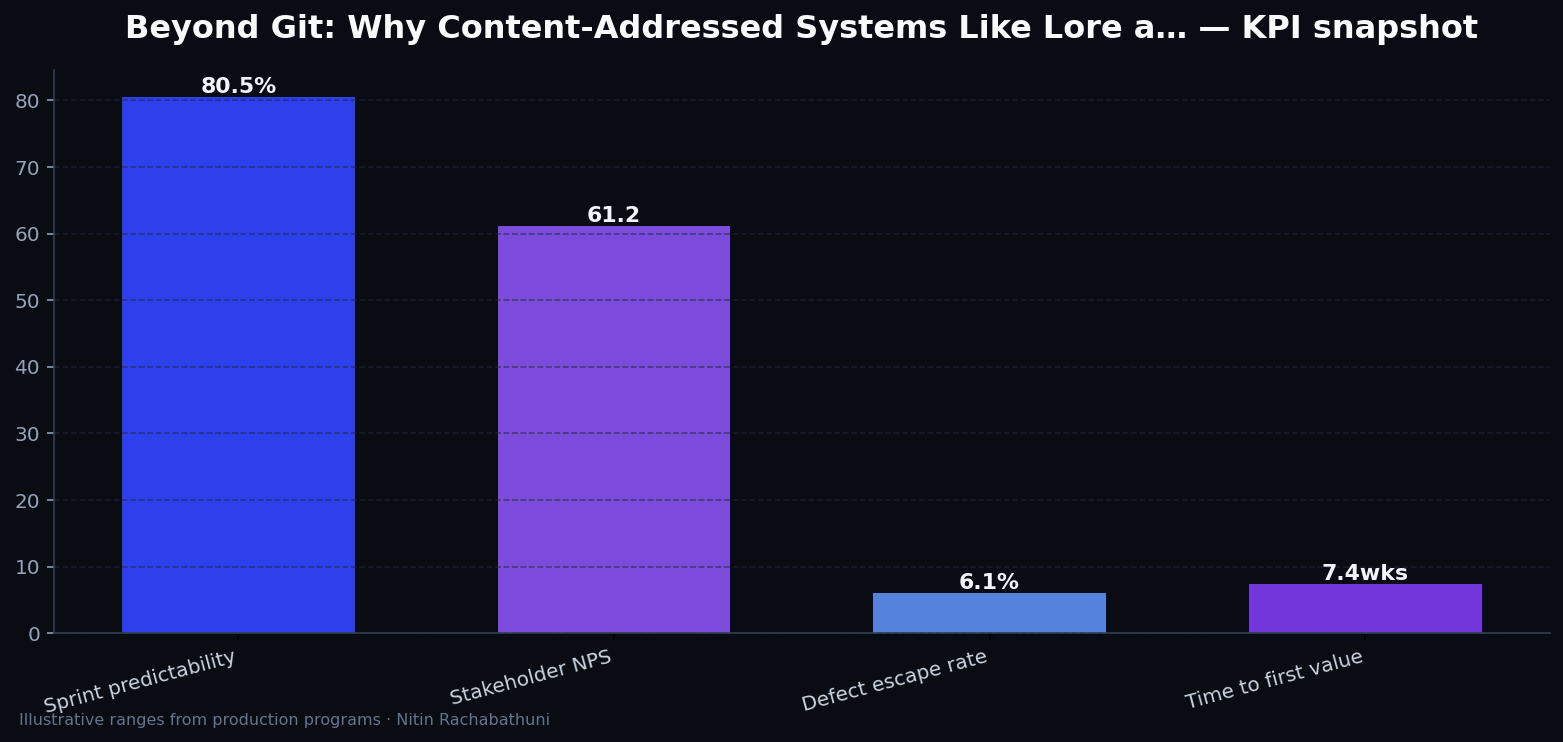
Illustrative consulting KPI ranges observed on programs like “Beyond Git: Why Content-Addressed Systems Like Lore a…” — validate against your own telemetry before setting SLOs. Methodology: production-like staging traces + weekly review with product and ops.
Architecture flow

Code sketches
/* Integration sketch */
// Beyond Git: Why Content-Addressed Systems Like Lore a…
export async function rolloutLoreVersionControlContentAddressedScalability() {
const checks = ["telemetry", "auth", "rollback"];
return { ok: true, checks };
}
Official references
Related on this site
Article slug: lore-version-control-content-addressed-scalability · Engineering notes by Nitin Rachabathuni — MVP in 2 days specialist.