The Shift from Experimental to Operational: The Rise of Local Inference
For the past year, the narrative surrounding Large Language Models (LLMs) has been dominated by the sheer power of frontier models accessible via cloud APIs. While these massive models are undeniably capable, a significant shift is occurring in the engineering landscape. We are moving away from "just use the biggest API" toward a more nuanced, hybrid approach where local inference is no longer just an experiment for hobbyists—it is becoming a strategic choice for production workflows.
The gap between what a local model can do and what a frontier cloud model provides is narrowing at an exponential rate. For many software engineering tasks, the "intelligence overhead" of a massive cloud model isn't always necessary. When you are performing repetitive tasks like unit test generation, boilerplate extraction, or—crucially—complex refactoring within a controlled environment, local models offer advantages that cloud APIs cannot match: data sovereignty, predictable latency, and significantly lower marginal costs per token.
Why Local Models Win in the Development Lifecycle
One of the strongest arguments for moving workloads to local inference is the "contextual loop." When an AI agent or a developer's tool needs to perform multiple iterations on a single piece of code—such as converting a messy Jupyter Notebook into a modular, production-ready repository—the number of API calls can skyrocket. In a cloud-only model, every iteration incurs costs and potential rate limits.
By running these models locally (or on private infrastructure), you create a "closed loop." The system can iterate, fail, and retry without the friction of external dependencies. This is particularly vital for:
- Refactoring Large Codebases: Where the AI needs to understand deep internal relationships that are better handled in a local environment where data doesn't leave your VPC.
- Automated Documentation: Generating docstrings and READMEs across thousands of files.
- Data Sanitization: Processing sensitive PII (Personally Identifiable Information) that should never touch a third-party server.
The Practical Trade-offs: Reality vs. Hype
While the transition to local models is promising, it isn't a magic bullet; it requires disciplined engineering. To successfully move from "trying out" local models to "deploying" them, teams must focus on three core pillars:
1. Benchmarking Your Specific Use Case
Don't rely on general leaderboard scores (like MMLU or HumanEval) as your only metric for success. A model that ranks high globally might still fail at your specific coding style or internal framework requirements. You must benchmark against your prompts and your token mix. If you are primarily doing code completion, a model optimized for coding will outperform a general-purpose giant every time.
2. Versioning and Reproducibility
When you move local, "it works on my machine" becomes a major risk. You must implement strict logging of the Model ID, the quantization level (e.g., 4-bit vs. 8-bit), and the specific prompt version used for every production call. Without this metadata, debugging a failed refactor or an inconsistent output becomes nearly impossible as models are updated or swapped.
3. The Canary Deployment Strategy
Never flip the switch on your entire engineering team at once. When moving a workflow from a cloud API to a local model, use a canary deployment strategy. Route low-risk tasks—such as generating comments or basic unit tests—to the local model first. Once you have established high confidence in its output consistency, move more complex architectural refactoring into the pipeline.
Building Your Roadmap for Local Integration
The transition isn't just about swapping an API key; it’s about re-architecting how your team interacts with AI. It involves setting up local inference servers (like vLLM or Ollama), managing GPU resources, and building robust evaluation pipelines to ensure that the "local" output matches the quality of the "cloud" standard.
If you are looking to navigate these complexities and want to build a custom, production-ready AI architecture tailored to your specific engineering needs, reaching out for expert guidance can accelerate your roadmap significantly. Get in touch for MVP help to discuss how to integrate local LLMs into your development workflow effectively.
Conclusion: The Hybrid Future
The future of AI in software engineering isn't a choice between "Local" and "Cloud"—it is the intelligent orchestration of both. Use cloud models for high-level creative reasoning and complex multi-step planning, but lean on local inference for the heavy lifting of code generation, refactoring, and private data processing. By moving your core development loops to local models now, you gain speed, security, and scalability that will define the next generation of software engineering.
Frequently Asked Questions
When should I choose a local model over a cloud API? Choose local models when data privacy is paramount, cost predictability for high-volume repetitive tasks is needed, or low-latency offline capabilities are required. This allows you to process sensitive information without it leaving your infrastructure while keeping costs predictable.
Are local models accurate enough for complex refactoring? Yes, modern quantized models (such as Llama 3 or Mistral variants) can handle significant architectural changes and code refactoring with high accuracy when prompted correctly. They are often more than sufficient for tasks that do not require real-time external data.
How do I manage versioning in a local LLM environment? You should log the specific model ID, quantization level, and prompt version for every production call to ensure consistency across your development pipeline. This allows you to track exactly which "version" of intelligence produced a specific piece of code.
Authoritative references
Consult Next.js documentation, MDN Web Docs, web.dev, Next.js documentation, OWASP Cheat Sheets alongside the official references block below. Cross-check guidance with your compliance, security, and SRE stakeholders before setting SLOs.
Metrics snapshot
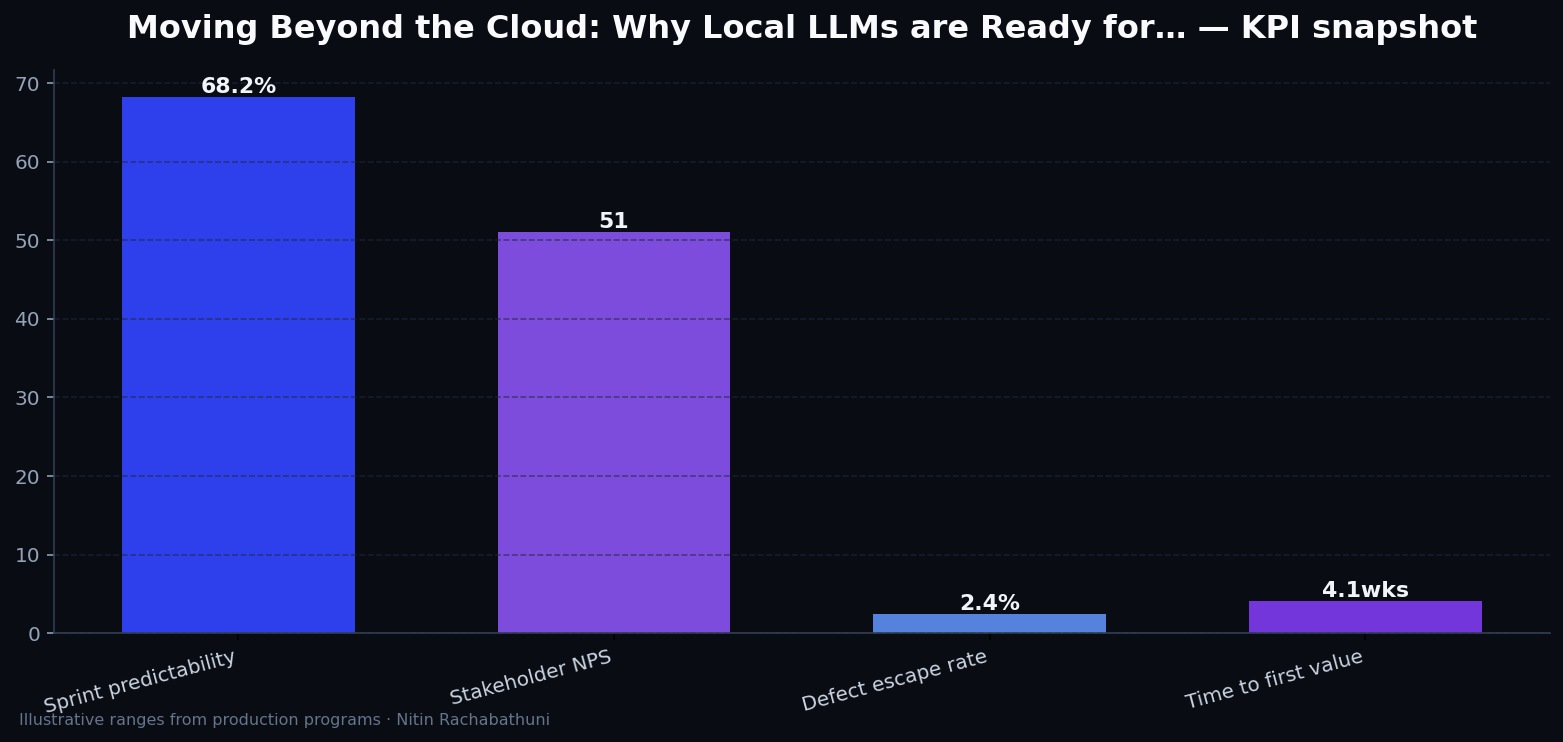
Illustrative consulting KPI ranges observed on programs like “Moving Beyond the Cloud: Why Local LLMs are Ready for…” — validate against your own telemetry before setting SLOs. Methodology: production-like staging traces + weekly review with product and ops.
Architecture flow

Code sketches
/* Integration sketch */
// Moving Beyond the Cloud: Why Local LLMs are Ready for…
export async function rolloutLocalLlmsProductionReadinessWorkflows() {
const checks = ["telemetry", "auth", "rollback"];
return { ok: true, checks };
}
Official references
Related on this site
Article slug: local-llms-production-readiness-workflows · Engineering notes by Nitin Rachabathuni — MVP in 2 days specialist.