The Rise of GLM-5.2: Navigating the Trade-offs of High-Reasoning Open Weights Models
The landscape of open weights models is evolving at a pace that often surprises even seasoned AI engineers. For years, the gap between proprietary giants and open alternatives was wide—a chasm defined by reasoning capabilities and nuanced instruction following. However, recent data from Artificial Analysis indicates that this gap is narrowing significantly.
GLM-5.2 has recently claimed the top spot on the intelligence index for open weights models. By outperforming notable competitors such as minimax-m3 and deepseek v4 pro in key benchmarks, it has established itself as a formidable contender for production environments where high-level reasoning is non-negotiable. Yet, as with any engineering decision involving large language models (LLMs), the "best" model isn't always the most efficient one for every specific use case.
The Reasoning vs. Efficiency Paradox
When evaluating GLM-5.2, it is critical to distinguish between raw intelligence and operational efficiency. The data shows that while GLM-5.2 achieves reasoning scores comparable to premium proprietary systems, there is a documented trade-off: its token efficiency lags behind many peers at similar intelligence levels.
In practical terms, this means that if your application requires complex logical deduction—such as multi-step mathematical problem solving or nuanced coding logic—GLM-5.2 provides the "brainpower" necessary to execute those tasks accurately. However, because it is less token-efficient than some of its competitors, you may find yourself consuming more tokens (and therefore incurring higher costs or hitting rate limits faster) to achieve the same output as a more streamlined model.
For engineering teams, this creates a strategic fork in the road:
- The Reasoning Path: Choose GLM-5.2 when accuracy and complex reasoning are the primary KPIs, even if it means a slightly higher overhead in token consumption.
- The Efficiency Path: Opt for models with higher token efficiency when your task is more straightforward (e.g., summarization or sentiment analysis) where "over-thinking" by the model isn't necessary but cost/latency control is vital.
Moving Beyond Benchmark Charts: Practical Engineering Strategies
One of the most common mistakes in AI integration is making a production decision based solely on an aggregate benchmark chart from a launch announcement. While Artificial Analysis provides invaluable data, these charts represent "clean" environments. Real-world applications involve messy prompts, varying context windows, and specific token mixes that can skew performance results.
To build a robust system using models like GLM-5.2, I recommend three core engineering practices:
1. Benchmark Your Specific Prompt Mix
Don't just look at the leaderboard; run your actual production prompts through both GLM-5.2 and its competitors. A model that excels in general reasoning might underperform on your specific "niche" task due to how it was fine-tuned or handled during RLHF (Reinforcement Learning from Human Feedback).
2. Granular Logging for Observability
When deploying a new open weights champion like GLM-5.2, you must maintain strict observability. Log the model_id and the specific prompt_version on every production call. This allows your team to perform A/B testing and regression analysis when comparing it against other models in your fleet.
3. Canary Deployments
Never switch a high-traffic endpoint to a new model overnight. Use canary deployments to route a small percentage of traffic (e.g., 5%) to GLM-5.2 on low-risk endpoints. This allows you to monitor for hallucinations, latency spikes, or unexpected costs before making it the default choice for your entire user base.
Strategic Integration and MVP Development
Choosing between high-reasoning models like GLM-5.2 and more efficient alternatives is a core part of building a scalable AI product. If you are currently navigating these technical trade-offs to build an MVP, it is essential to have a roadmap that balances "bleeding edge" capabilities with operational stability.
If you need expert guidance on architecting your LLM stack or moving from prototype to production while balancing cost and performance, contact me for MVP help to ensure your infrastructure is built for scale.
Conclusion: The Nuance of Selection
GLM-5.2 represents a significant milestone in the open weights ecosystem. It proves that high-level reasoning is no longer exclusive to proprietary models. However, its emergence also highlights the necessity of careful engineering. By understanding the trade-offs between intelligence and token efficiency—and by implementing rigorous testing protocols like canary deployments and specific prompt benchmarking—you can leverage these powerful models without falling into common pitfalls of "hype-driven" development.
The goal isn't just to find the smartest model; it’s to find the most effective model for your specific production constraints.
Authoritative references
Consult Next.js documentation, MDN Web Docs, web.dev, Next.js documentation, OWASP Cheat Sheets alongside the official references block below. Cross-check guidance with your compliance, security, and SRE stakeholders before setting SLOs.
Metrics snapshot
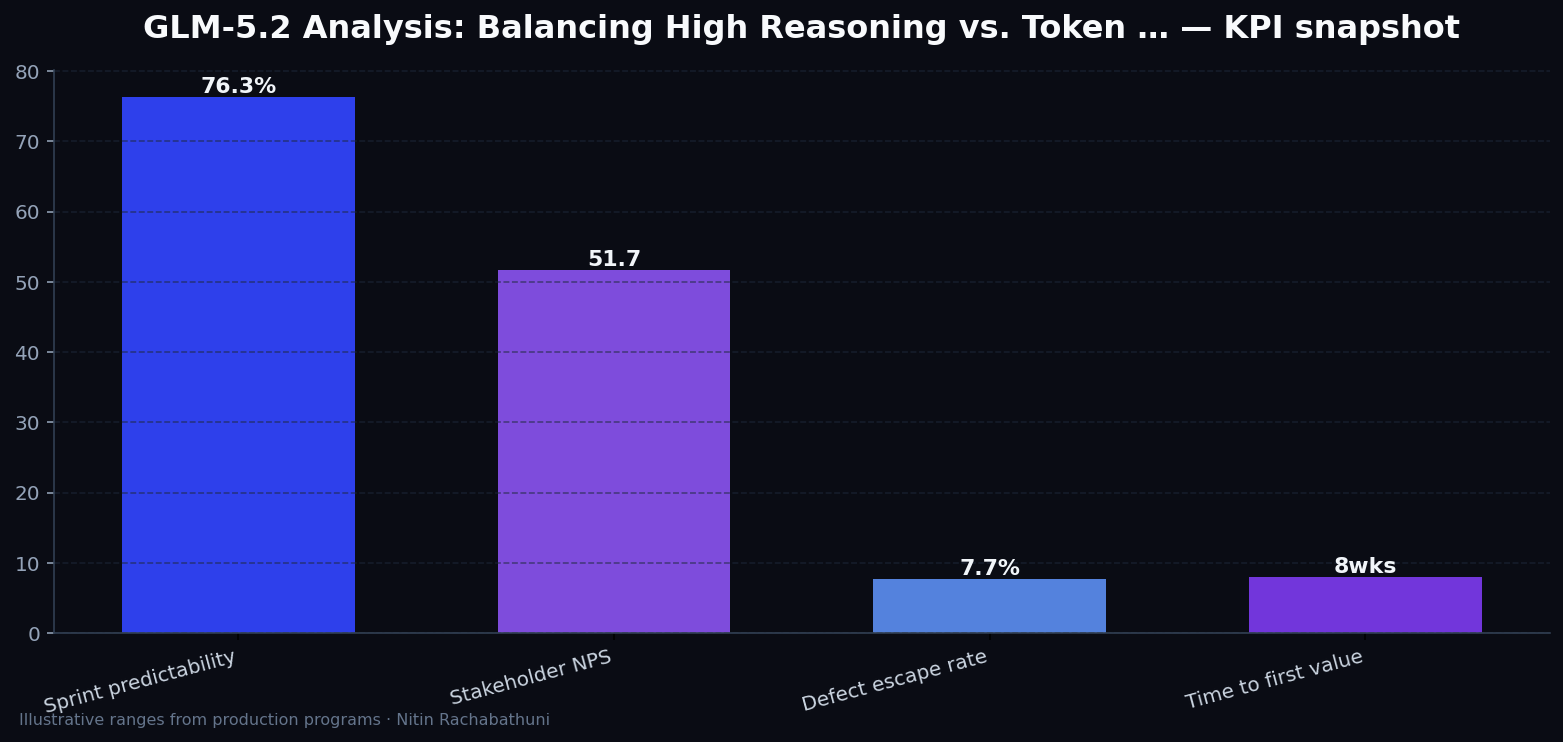
Illustrative consulting KPI ranges observed on programs like “GLM-5.2 Analysis: Balancing High Reasoning vs. Token …” — validate against your own telemetry before setting SLOs. Methodology: production-like staging traces + weekly review with product and ops.
Architecture flow

Code sketches
/* Integration sketch */
// GLM-5.2 Analysis: Balancing High Reasoning vs. Token …
export async function rolloutGlm52OpenWeightsAnalysisIntelligenceIndex() {
const checks = ["telemetry", "auth", "rollback"];
return { ok: true, checks };
}
Official references
Related on this site
Article slug: glm-5-2-open-weights-analysis-intelligence-index · Engineering notes by Nitin Rachabathuni — MVP in 2 days specialist.