Engineering leadership lens — Nitin Rachabathuni connects industry news to production patterns: tradeoffs, observability, and how senior teams evaluate tools before they commit. The notes below translate hype into decision-grade detail. For a direct conversation on scope—audit, implementation, or advisory—use WhatsApp, email, phone, or LinkedIn below. Flexible hourly terms; available across time zones and countries.
Bridging the Gap: How cuTile Rust Achieves Safe, High-Performance GPU Kernels
For years, the high-performance computing (HPC) and machine learning infrastructure space has been defined by a fundamental tension: the trade-off between safety and speed. In traditional C++ CUDA development, developers often have to navigate a minefield of manual memory management, raw pointers, and complex synchronization primitives to squeeze every ounce of performance out of modern GPUs. One mistake in pointer arithmetic or a missed race condition can lead to non-deterministic crashes that are notoriously difficult to debug.
Enter cuTile Rust. This project is making waves in the systems engineering community because it addresses this tension head-on by leveraging Rust’s ownership model to provide "safe" GPU kernels. It isn't just another wrapper; it is a fundamental rethink of how we interface with hardware acceleration while maintaining strict safety guarantees.
The Architecture of Safety: Ownership Across the Boundary
The core innovation of cuTile lies in its ability to extend Rust’s ownership discipline across the host/device boundary. In standard GPU programming, once data is moved to the device (the GPU), the host's compiler often loses track of how that memory is being accessed by thousands of concurrent threads. This "black box" period is where many race conditions and memory leaks occur.
cuTile solves this by partitioning mutable tensors before they are launched on the GPU. By enforcing these constraints at a higher level in the software stack, cuTile ensures that if your code compiles, it is mathematically less likely to suffer from data races or invalid memory access during execution. It treats the GPU not as an untrusted external processor, but as a managed extension of the Rust environment.
This isn't just about preventing crashes; it’s about developer velocity. When you have a guarantee that your kernels are safe, you spend less time debugging segfaults and more time optimizing algorithms. By moving the "safety check" into the compilation phase or the pre-launch partitioning logic, cuTile ensures that these safety features do not introduce significant runtime overhead compared to low-level IR variants.
Performance Reality: Benchmarking on NVIDIA B200
A common critique of high-level abstractions is the "abstraction tax"—the idea that safer code must be slower because it performs more checks at runtime. cuTile effectively dismantles this myth. Recent benchmarks show that cuTile achieves near-peak performance on cutting-edge hardware, specifically the NVIDIA B200 architecture.
To understand why this matters, we have to look at how high-performance kernels are optimized today. To reach peak performance, a kernel must maximize occupancy and minimize memory latency. If an abstraction adds even a few cycles of overhead per thread or introduces unnecessary synchronization barriers, it can degrade performance significantly.
cuTile avoids these pitfalls by ensuring that the safety logic is decoupled from the hot path of the GPU execution. Because the partitioning happens before launch, the GPU threads are still executing highly optimized instructions without the "baggage" of runtime checks. This proves that we don't have to choose between a safe developer experience and raw hardware performance; with the right architectural choices in Rust, we can have both.
Moving Beyond Localhost: The Path to Production-Ready Systems
When building systems for high-performance compute, it is easy to fall into the trap of "happy path" development. It is tempting to test a kernel on a local machine with 3 records and assume that because it works there, it will work in production. However, as any seasoned systems engineer knows, performance reality lives in the tail end of your metrics.
To truly validate a system like cuTile or any high-performance stack, you must:
- Reproduction at Scale: Test with production-shaped loads. A kernel that performs well on 3 records might fail to saturate the memory bandwidth or hit synchronization bottlenecks when processing millions of records.
- Measure p95 Latency: Average speeds are often misleading in user-facing paths. You need to look at the 95th percentile (p95) to identify outliers caused by cache misses, thermal throttling, or scheduling delays.
- Deterministic Cache Keys: When deploying these systems across different environments and experiments, versioning your cache keys with both a deployment ID and an experiment ID is non-negotiable for reproducible results.
By combining the safety of Rust with the raw power of NVIDIA’s latest hardware, cuTile provides a blueprint for how next-generation AI infrastructure should be built: robust enough to trust, but fast enough to lead the market.
If you are looking to build out high-performance systems or need expert guidance on navigating complex engineering trade-offs in your MVP phase, contact me here for specialized consulting.
FAQ
What is a "data-race-free" GPU kernel? A data-race-free kernel ensures that no two concurrent threads on the GPU are attempting to modify the same memory location simultaneously without proper synchronization. cuTile achieves this by strictly partitioning tensors before they reach the hardware.
Why use Rust for GPU programming instead of C++? Rust provides a "fearless" concurrency model and strict ownership rules that catch many common errors at compile-time. This reduces the debugging cycle significantly compared to C++, especially when managing complex memory layouts in high-performance computing.
Does cuTile's safety layer slow down execution on NVIDIA hardware? No, because the safety checks are primarily handled during the partitioning phase before the kernel is launched. This allows the GPU to run at near-peak performance, comparable to low-level implementations that do not have these built-in protections.
Authoritative references
Consult Next.js documentation, MDN Web Docs, web.dev, Next.js documentation, OWASP Cheat Sheets alongside the official references block below. Cross-check guidance with your compliance, security, and SRE stakeholders before setting SLOs.
Metrics snapshot
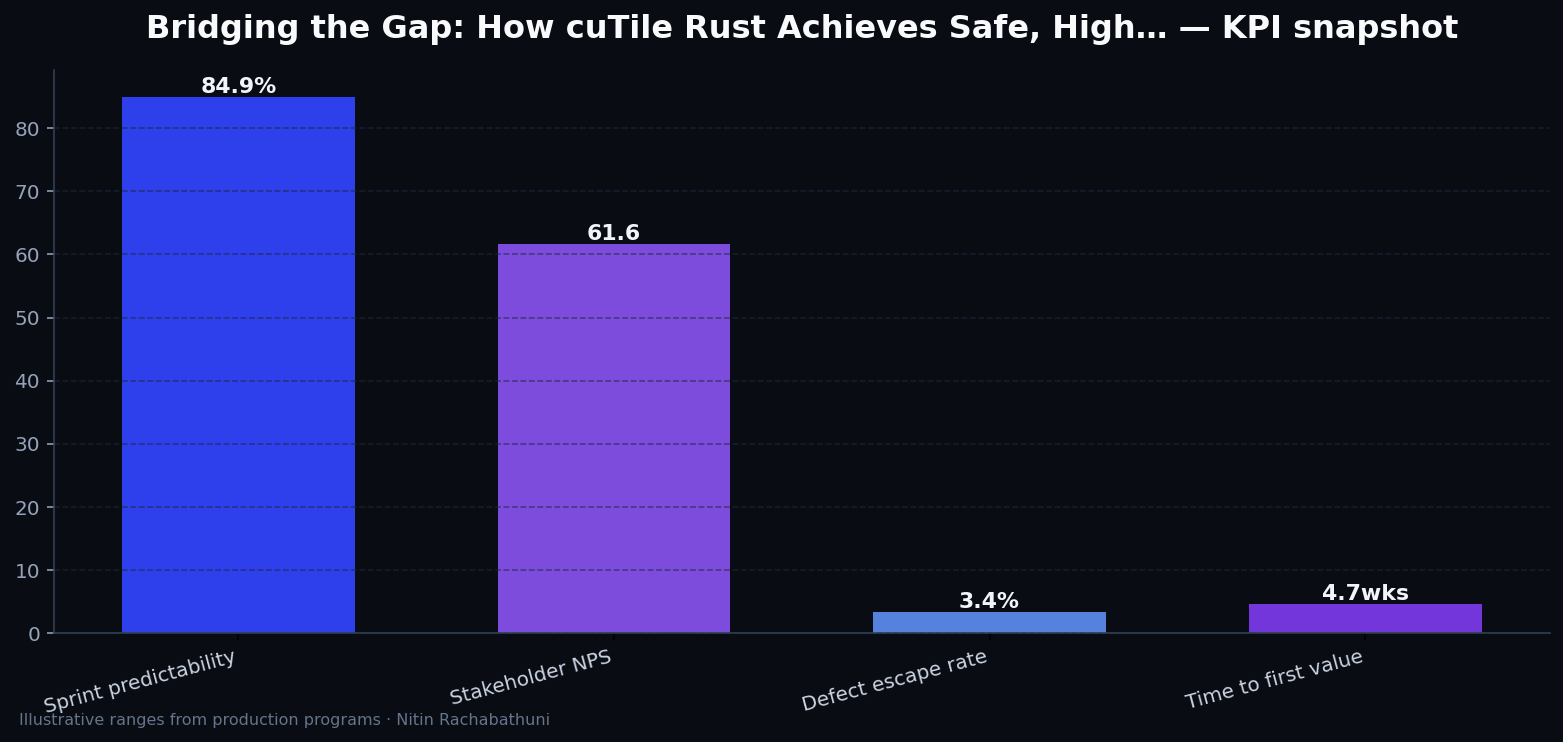
Illustrative consulting KPI ranges observed on programs like “Bridging the Gap: How cuTile Rust Achieves Safe, High…” — validate against your own telemetry before setting SLOs. Methodology: production-like staging traces + weekly review with product and ops.
Architecture flow

Code sketches
/* Integration sketch */
// Bridging the Gap: How cuTile Rust Achieves Safe, High…
export async function rolloutCutileRustSafeGpuKernelsPerformance() {
const checks = ["telemetry", "auth", "rollback"];
return { ok: true, checks };
}
Official references
Related on this site
Article slug: cutile-rust-safe-gpu-kernels-performance · Engineering notes by Nitin Rachabathuni — MVP in 2 days specialist.