The Persistence of Network Realities in the Cloud Era
In the world of software engineering, there is a recurring trap: the belief that modern infrastructure has solved the fundamental problems of networking. Because we live in an era of high-speed fiber optics, 5G connectivity, and massive cloud providers like AWS and Azure, it is easy to fall into the "illusion of perfection." We start to believe that because our local development environment feels instantaneous and reliable, the production network will behave with the same grace.
This is where the "fallacies of distributed computing" become vital. Originally identified as a way to warn engineers about common misconceptions when moving from monolithic architectures to distributed systems, these principles remain just as relevant in 2015 as they were in the late 90s. When you move logic across a network—whether it is between two containers in a Kubernetes pod or two data centers on opposite sides of the globe—you are introducing variables that your local machine cannot simulate: packet loss, jitter, out-of-order delivery, and partial failures.
Ignoring these realities doesn't just lead to "slow" apps; it leads to catastrophic system failures where one slow service causes a cascading failure across the entire architecture. To build resilient systems today, we must design for the reality of the wire, not the fantasy of the local loopback.
The Core Fallacies: From Latency to Security
When we break down the core fallacies that still plague modern backend engineering, several key themes emerge that every architect should prioritize during the design phase.
1. The Myth of Zero Latency
Many developers write code as if a remote procedure call (RPC) is just as fast as a local function call. They might omit timeouts or fail to account for "tail latency." In reality, even a well-optimized network hop has overhead. If your system assumes that every request will return in 10ms, it will buckle when the p99 and p99.9 metrics spike due to network congestion. We must measure performance using production-shaped loads—not just three rows of data on localhost—to see how the system behaves under stress.
2. The Fallacy of Infinite Bandwidth
While bandwidth is plentiful, it is not infinite or guaranteed. Large payloads over a network can saturate pipes, leading to throttled speeds and dropped packets. Engineers must be mindful of payload sizes; if you are sending megabytes of data for every small API call, you are inviting instability into your system's throughput.
3. The Illusion of Reliable Networks
The most dangerous assumption is that the network will always "work." Packets get lost. Routers crash. ISP routes change. A distributed system must be designed to handle these failures gracefully. This means implementing retries with exponential backoff and jitter, as well as circuit breakers that stop the flow of requests to a failing downstream service before it can overwhelm the entire ecosystem.
4. The Myth of Secure Networks
One of the most common mistakes in modern microservices is assuming that "internal" traffic doesn't need encryption or strict authentication because it isn't exposed to the public internet. This creates a massive security hole. If an attacker gains access to one minor service, they can move laterally through your network with ease if every internal communication assumes a "trusted" environment. Zero Trust Architecture is not just a buzzword; it is the necessary response to this fallacy.
Engineering for Resilience: Practical Strategies
Moving from theory to practice requires changing how we write code and configure our infrastructure. Here are three concrete ways to address these fallacies in your daily workflow:
Implement Idempotency: Since networks can fail after a command is executed but before the acknowledgment reaches you, retries can lead to duplicate actions (like charging a customer twice). Designing idempotent APIs ensures that performing the same operation multiple times has the same effect as doing it once.
Observe the Tail Latency: Average response times are often misleading because they hide the "outliers" that ruin user experience. Focus on p95 and p99 metrics to understand how your system behaves for the users who are experiencing the most friction. If a service is slow 1% of the time, but those 1% represent thousands of frustrated customers, you have a problem.
Decouple with Message Queues: When possible, move from synchronous requests to asynchronous processing. By using message brokers (like RabbitMQ or Kafka), you decouple the immediate success of an action from the network's reliability at that specific moment. If the downstream service is down, the message stays in the queue until it can be processed.
If you are looking to build a robust MVP and need expert guidance on navigating these complex architectural trade-offs, contact Nitin Rachabathuni for specialized consulting to help scale your vision correctly from the ground up.
Conclusion: Designing for Failure as a First Principle
The "fallacies of distributed computing" are not just academic hurdles; they are the boundaries within which all reliable software must operate. As we move further into an era of edge computing, 5G, and hyper-distributed microservices, these risks only multiply.
We cannot build systems that assume perfect reliability simply because our current infrastructure feels stable. We must design for failure as a first principle—assuming the network will be slow, the packets will get lost, and the internal services are not inherently "safe." By acknowledging these truths early in the development cycle, we can build systems that don't just work when everything is perfect, but continue to function gracefully when things go wrong.
Frequently Asked Questions
What is a fallacy of distributed computing? A fallacy of distributed computing is a common but incorrect assumption made by developers when designing systems that communicate over a network. These fallacies lead to brittle, insecure, or slow applications because they ignore the inherent unreliability and latency of networks.
Does high-speed fiber mean we can ignore network latency? No. Even with modern infrastructure, physical distance and hardware processing still introduce non-negligible delays. Relying on "zero latency" leads to poor user experience when the system encounters even minor congestion or routing changes.
How can developers mitigate these fallacies in microservices? Developers should implement patterns like retries with exponential backoff, circuit breakers, and idempotent operations. Additionally, using proper timeouts and ensuring all internal communication is encrypted helps address the core risks of distributed systems.
Authoritative references
Consult Next.js documentation, MDN Web Docs, web.dev, Next.js documentation, OWASP Cheat Sheets alongside the official references block below. Cross-check guidance with your compliance, security, and SRE stakeholders before setting SLOs.
Metrics snapshot
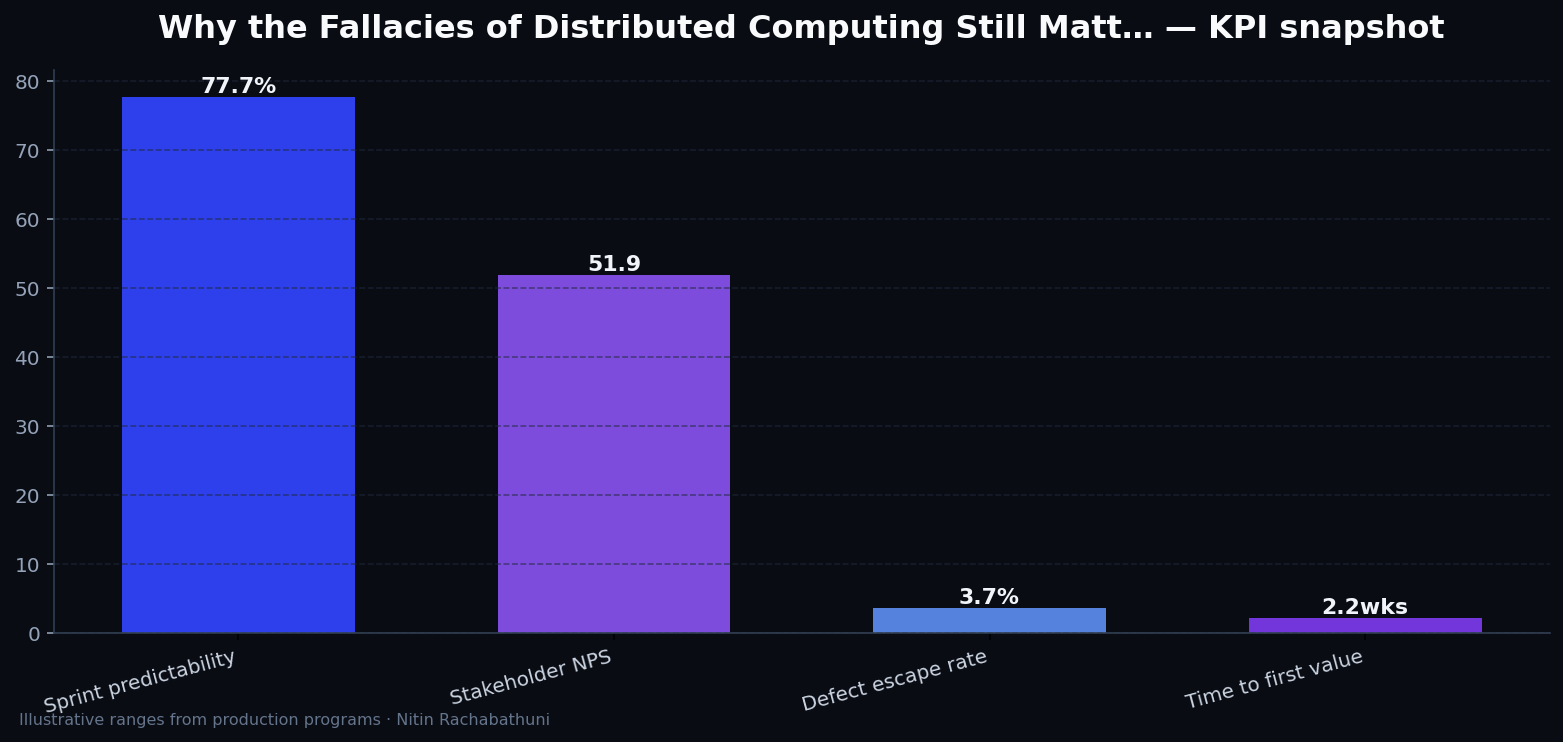
Illustrative consulting KPI ranges observed on programs like “Why the Fallacies of Distributed Computing Still Matt…” — validate against your own telemetry before setting SLOs. Methodology: production-like staging traces + weekly review with product and ops.
Architecture flow

Code sketches
/* Integration sketch */
// Why the Fallacies of Distributed Computing Still Matt…
export async function rolloutFallaciesOfDistributedComputing2025() {
const checks = ["telemetry", "auth", "rollback"];
return { ok: true, checks };
}
Official references
Related on this site
Article slug: fallacies-of-distributed-computing-2025 · Engineering notes by Nitin Rachabathuni — MVP in 2 days specialist.