Beyond Static Analysis: Why Execution-Based AI Code Review is the Next Frontier
In the current era of rapid software delivery, we have become accustomed to a certain level of "hallucinated safety." We use LLMs to generate boilerplate, and we increasingly use them to review pull requests (PRs). However, there is a fundamental ceiling to what an LLM can do when it only has access to text.
Most AI code reviewers today are performing static analysis. They look at the lines of code you just wrote and compare them against their training data to see if they "look" correct. While this catches syntax errors or obvious logic flaws, it fails to catch the most insidious bugs: those that only emerge when the code actually touches a database, hits an API endpoint, or handles a concurrent request.
The emergence of tools like TREX marks a shift from static interpretation to dynamic execution. This is not just a technical upgrade; it is a leadership shift in how we define "verified" code before it hits production.
The Gap Between "Clean Code" and "Working Software"
As engineering leaders, we often find ourselves caught between two metrics: code quality and system reliability. A PR can be beautifully formatted, follow every SOLID principle, and pass all linting rules—yet still crash the production environment because of a misconfigured environment variable or a timeout that only triggers under specific load conditions.
When an AI reviewer only reads text, it is guessing at your intent based on patterns. When an AI reviewer runs your code in a sandboxed environment (the core innovation behind TREX), it is validating your reality.
By moving to execution-based review, the feedback loop changes:
- From "Does this look right?" $\rightarrow$ "Did this actually work?"
- From "Identify potential bugs." $\rightarrow$ "Report actual failures."
This transition requires a move away from simple prompt engineering toward robust infrastructure. To make an AI effective at execution-based review, it needs more than just the diff; it needs context—logs, traces, and screenshots generated by the runtime environment. This multi-modal data allows the model to "see" why a test failed or where a bottleneck occurred in the stack.
The Infrastructure of Execution: Moving Beyond Prompting
The reason most teams haven't adopted execution-based AI review yet is that it is significantly harder to build than a standard wrapper around an LLM. To move from static to dynamic, you have to solve three primary engineering hurdles:
1. Sandboxed Environments
You cannot run untrusted code on your production servers or even in shared dev environments. You need disposable, isolated containers where the AI can execute the code and capture the output safely. This ensures that if a PR contains a "poison pill" (like an infinite loop), it only takes down a temporary container.
2. Artifact Generation
An LLM is much better at diagnosing a problem when it has evidence. Instead of just showing the AI the code, we provide it with:
- Logs: To see exactly where the execution path diverged from expectations.
- Traces: To understand latency and hop-by-hop failures in microservices.
- Screenshots/DOM states: For front-end components to ensure visual integrity.
3. Contextual Indexing
The AI needs to know how the new code interacts with the existing codebase. By indexing the entire repository, the system can provide the LLM with relevant snippets of neighboring modules when it analyzes a failure in the execution layer.
Leadership Implications: Moving from Localhost to Production-Scale Thinking
For engineering leaders and architects, this shift changes our requirements for "Done." If we want to move toward high-reliability systems, we must stop accepting "it works on my machine" as a valid status.
When integrating these advanced AI layers into your CI/CD pipeline, the leadership focus should shift toward three specific areas:
- Realistic Load Simulation: Don't just run the code with one record in a mock database. The execution layer should ideally be exposed to production-shaped load so that concurrency issues are caught early.
- Observability as Validation: If your AI reviewer can’t see the logs or traces, it is effectively blind. We must prioritize observability tools (like OpenTelemetry) not just for debugging, but as a primary input for our automated review systems.
- Reliable Metrics: Stop looking at average success rates. In high-stakes environments, we need to measure p95 and p99 latencies before and after the AI intervention to ensure that "cleaner" code is actually performing better under stress.
Building Your MVP for Execution-Based Review
Transitioning your entire pipeline to an execution-based model doesn't have to happen overnight. Start by identifying high-risk areas—such as payment processing, authentication flows, or complex state machines—where a "looks good" review isn't enough.
By implementing a sandboxed execution layer for these specific modules, you can begin to bridge the gap between code that looks correct and software that actually works. This is where we move from simple automation to true intelligent systems engineering.
If you are looking to build out your own internal tools or need help navigating the complexities of integrating advanced AI into your development lifecycle, contact me for MVP assistance to turn these high-level concepts into production-ready features.
Conclusion: The Future is Dynamic
The next generation of developer tools won't just be better at writing code; they will be better at verifying it. By moving toward execution-based review, we reduce the cognitive load on human reviewers and ensure that by the time a PR reaches a human eye, the "runtime" questions have already been answered by the system.
Authoritative references
Consult Next.js documentation, MDN Web Docs, web.dev, Next.js documentation, OWASP Cheat Sheets alongside the official references block below. Cross-check guidance with your compliance, security, and SRE stakeholders before setting SLOs.
Metrics snapshot
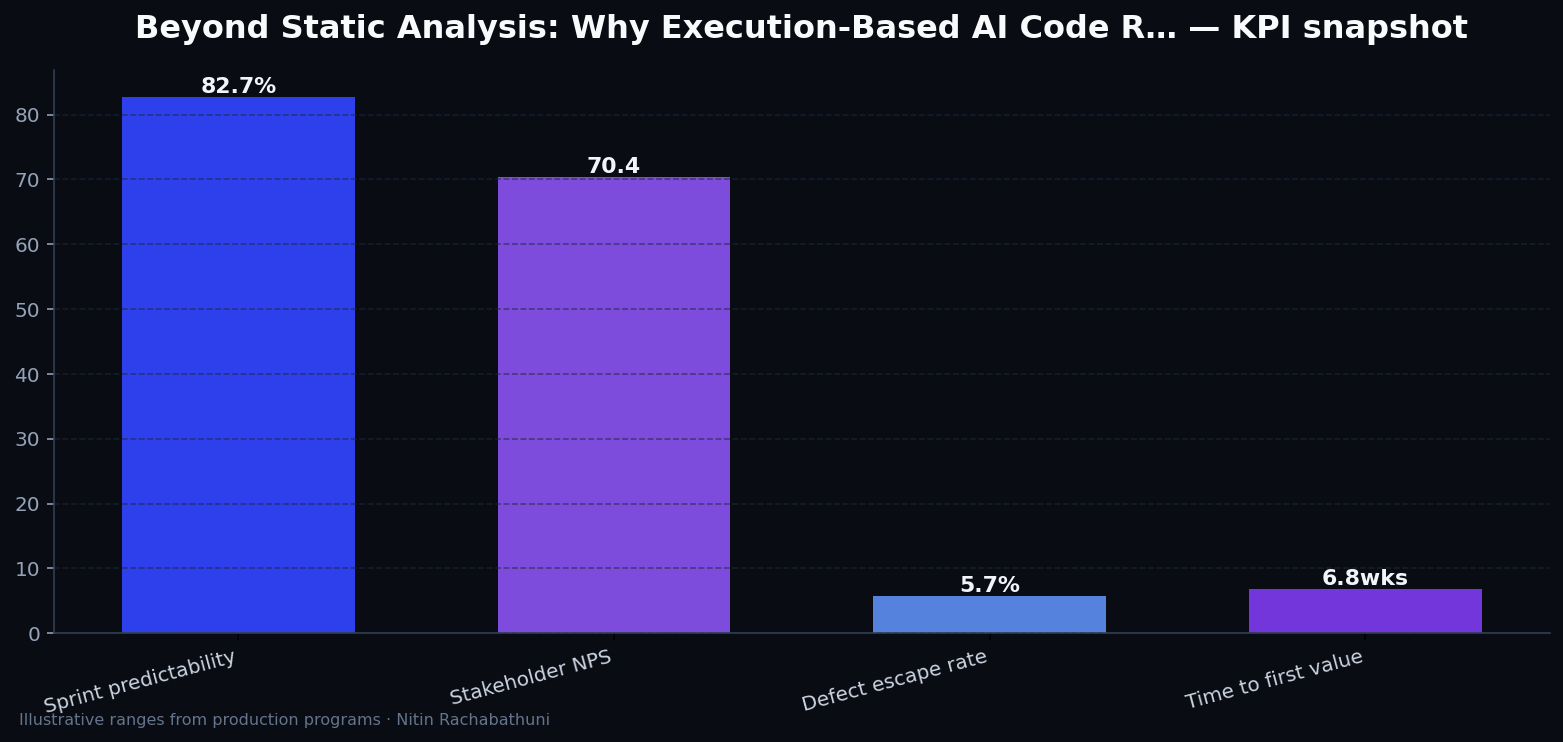
Illustrative consulting KPI ranges observed on programs like “Beyond Static Analysis: Why Execution-Based AI Code R…” — validate against your own telemetry before setting SLOs. Methodology: production-like staging traces + weekly review with product and ops.
Architecture flow

Code sketches
/* Integration sketch */
// Beyond Static Analysis: Why Execution-Based AI Code R…
export async function rolloutExecutionBasedAiCodeReviewTrex() {
const checks = ["telemetry", "auth", "rollback"];
return { ok: true, checks };
}
Official references
Related on this site
Article slug: execution-based-ai-code-review-trex · Engineering notes by Nitin Rachabathuni — MVP in 2 days specialist.