The Fallacy of the Flat Vector Store
In the early days of Retrieval-Augmented Generation (RAG), the standard playbook was simple: take your data, chunk it into pieces, turn those chunks into embeddings, and shove them into a vector database. While this approach works for basic "chat with your PDF" use cases, it falls apart when you attempt to build an autonomous agent capable of long-term reasoning or complex task execution.
The primary reason is that most early systems treat "memory" as a flat, undifferentiated pool of information. When an LLM queries such a system, the retrieval engine returns chunks based on mathematical proximity in vector space. However, human memory—and by extension, effective agentic logic—is structured. We distinguish between semantic knowledge (what is a hammer?), episodic memories (the time I used that hammer to fix the fence), and procedural instructions (how do I use this tool safely?).
When you collapse these into one flat vector space, "noise" becomes inevitable. An agent might retrieve an old instruction from three months ago because it is mathematically similar to a current task, even though that information is now obsolete or overridden by newer context. To build production-grade persistence, we must move toward a multi-layered architecture that mirrors these cognitive structures.
Architecting Multi-Layered Memory Structures
To achieve high recall and accuracy—such as the 0.89 recall seen in recent benchmarks using Elasticsearch—developers need to implement a tiered indexing strategy. Instead of one massive index, segment your data based on its functional role:
- Semantic Index: This stores core facts and world knowledge. It is updated infrequently and serves as the "foundation" for the agent's understanding.
- Episodic Index: This captures specific interactions, past successes, and failures. These are time-sensitive and should be weighted by recency.
- Procedural/Instructional Index: This contains the "rules of engagement," system prompts, and operational workflows.
By separating these into distinct indices (or using metadata filtering to isolate them), you can apply different retrieval logic to each. For example, when an agent is trying to figure out how to perform a task, it should prioritize the Procedural Index; when it's reflecting on its past performance, it queries the Episodic Index.
The Power of Hybrid Search: BM25 + Dense Vectors
One of the most significant technical hurdles in building reliable memory is "semantic drift." Sometimes, a vector search might find something that sounds like the right answer but isn't technically correct because it lacks specific keyword precision. This is where hybrid search becomes non-negotiable for production systems.
By combining BM25 (keyword-based) and dense vectors (embedding-based), you capture both the "vibe" of a query and the exact terminology required. In an Elasticsearch implementation, this involves using Reciprocal Rank Fusion (RRF). RRF merges the results from both search methods into a single ranked list without requiring complex weight tuning for every specific query.
To further refine this, adding a cross-encoder reranking step is highly effective. While vector models are great at finding "candidates," a cross-encoder can look at the top 10–20 results and perform a much more intensive analysis to determine which one actually satisfies the prompt's constraints. This two-step process—broad retrieval followed by surgical ranking—is what separates hobbyist projects from production-grade AI agents.
Handling Conflict, Decay, and Statefulness
A major pain point in agentic workflows is "conflicting information." If a user changes their preference (e.g., moving from "I like blue" to "Actually, I prefer red"), the vector database will still contain both statements. Without logic to handle this, the LLM may flip-flop between preferences depending on which chunk happens to be closer in the vector space.
To solve this, you must implement supersession logic. This involves tagging data with versioning or timestamps and using a "decay" function. If two pieces of information conflict, the system should prioritize the one with the most recent timestamp or the highest frequency of use.
Furthermore, implementing stateful memory requires tracking the context of an interaction. Not every piece of information is relevant forever; some are only relevant for the current session. By tagging data as "session-specific" vs. "global," you can filter out noise and ensure that the agent stays focused on the task at hand rather than getting lost in a labyrinth of irrelevant historical context.
Moving from Prototype to Production
Building an intelligent memory layer isn't just about choosing the right database; it’s about designing the data flow correctly. You need to consider:
- Metadata Filtering: Using attributes like
user_id,session_id, andcontent_typeto prune the search space before the LLM even sees it. - Evaluation Loops: Regularly testing your retrieval with "golden" datasets to ensure that updates to your embedding model or index structure don't degrade performance.
- Logging & Observability: Tracking which chunks are retrieved most often and why they were chosen, allowing you to prune low-value data from the system.
If you are looking to move beyond a basic RAG prototype and need help architecting a production-grade agent memory system or implementing complex hybrid search pipelines on Elasticsearch, get in touch for MVP development assistance. We specialize in building robust infrastructure that handles the nuances of stateful AI interactions.
FAQ
Q: Why is RRF better than simple weighted scoring for hybrid search? A: RRF (Reciprocal Rank Fusion) provides a more stable way to combine different types of scores—like BM25 and vector similarity—because it doesn't require you to normalize the weights between two completely different mathematical scales.
Q: How does "supersession" help with conflicting information? A: Supersession logic identifies when new data replaces old data. By checking timestamps or version tags during the retrieval phase, the system can ignore outdated facts that would otherwise confuse the LLM's decision-making process.
Q: What is the difference between a cross-encoder and an embedding model in reranking? A: An embedding model (bi-encoder) is fast but less precise for ranking because it compares "pre-calculated" vectors; a cross-encoder processes the query and the document together, providing much higher accuracy at the cost of more compute.
Authoritative references
Consult Next.js documentation, MDN Web Docs, web.dev, Next.js documentation, OWASP Cheat Sheets alongside the official references block below. Cross-check guidance with your compliance, security, and SRE stakeholders before setting SLOs.
Metrics snapshot
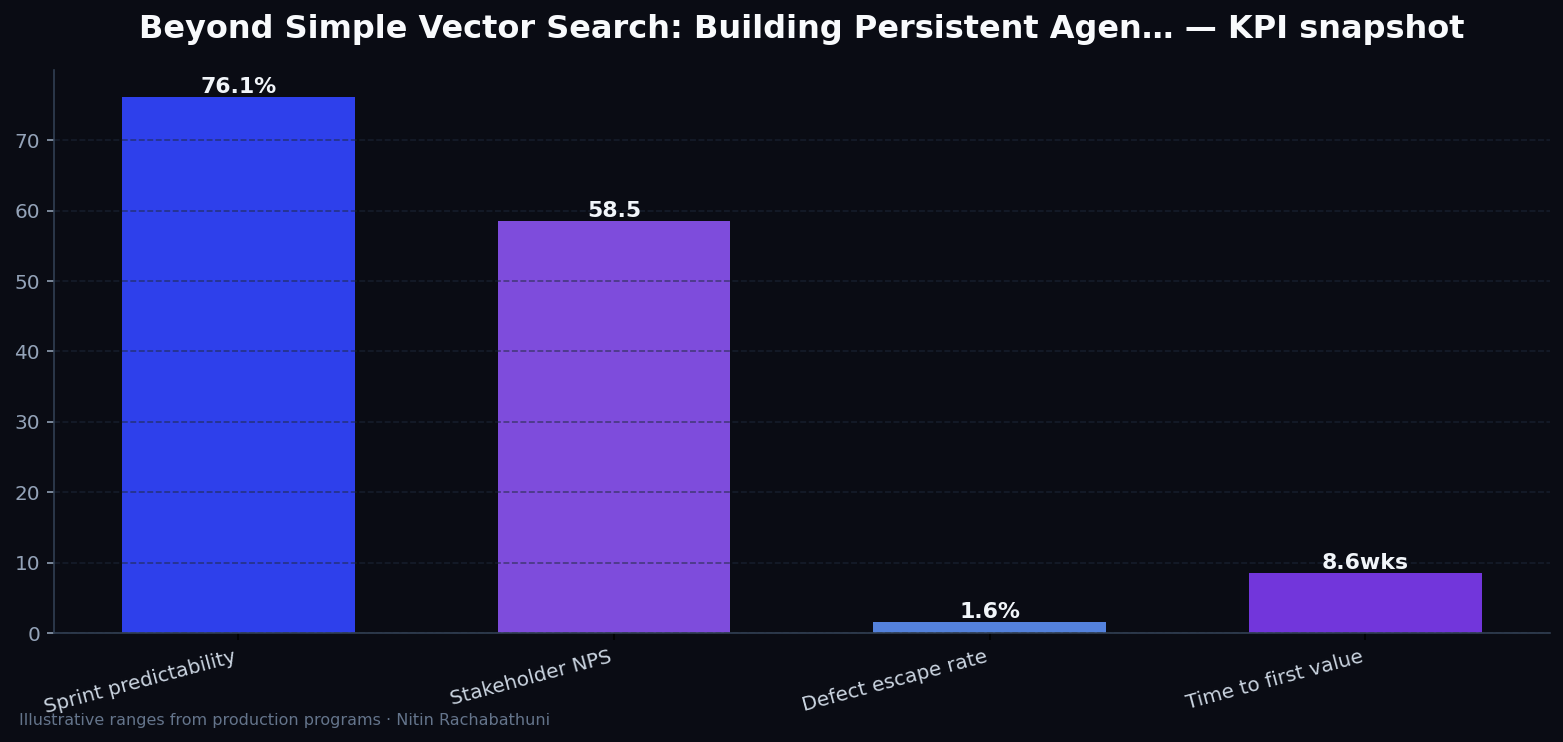
Illustrative consulting KPI ranges observed on programs like “Beyond Simple Vector Search: Building Persistent Agen…” — validate against your own telemetry before setting SLOs. Methodology: production-like staging traces + weekly review with product and ops.
Architecture flow

Code sketches
/* Integration sketch */
// Beyond Simple Vector Search: Building Persistent Agen…
export async function rolloutBuildingPersistentAgentMemoryElasticsearch() {
const checks = ["telemetry", "auth", "rollback"];
return { ok: true, checks };
}
Official references
Related on this site
Article slug: building-persistent-agent-memory-elasticsearch · Engineering notes by Nitin Rachabathuni — MVP in 2 days specialist.