Decoupling Postgres: Understanding the LTAP Architecture for Modern Data Scaling
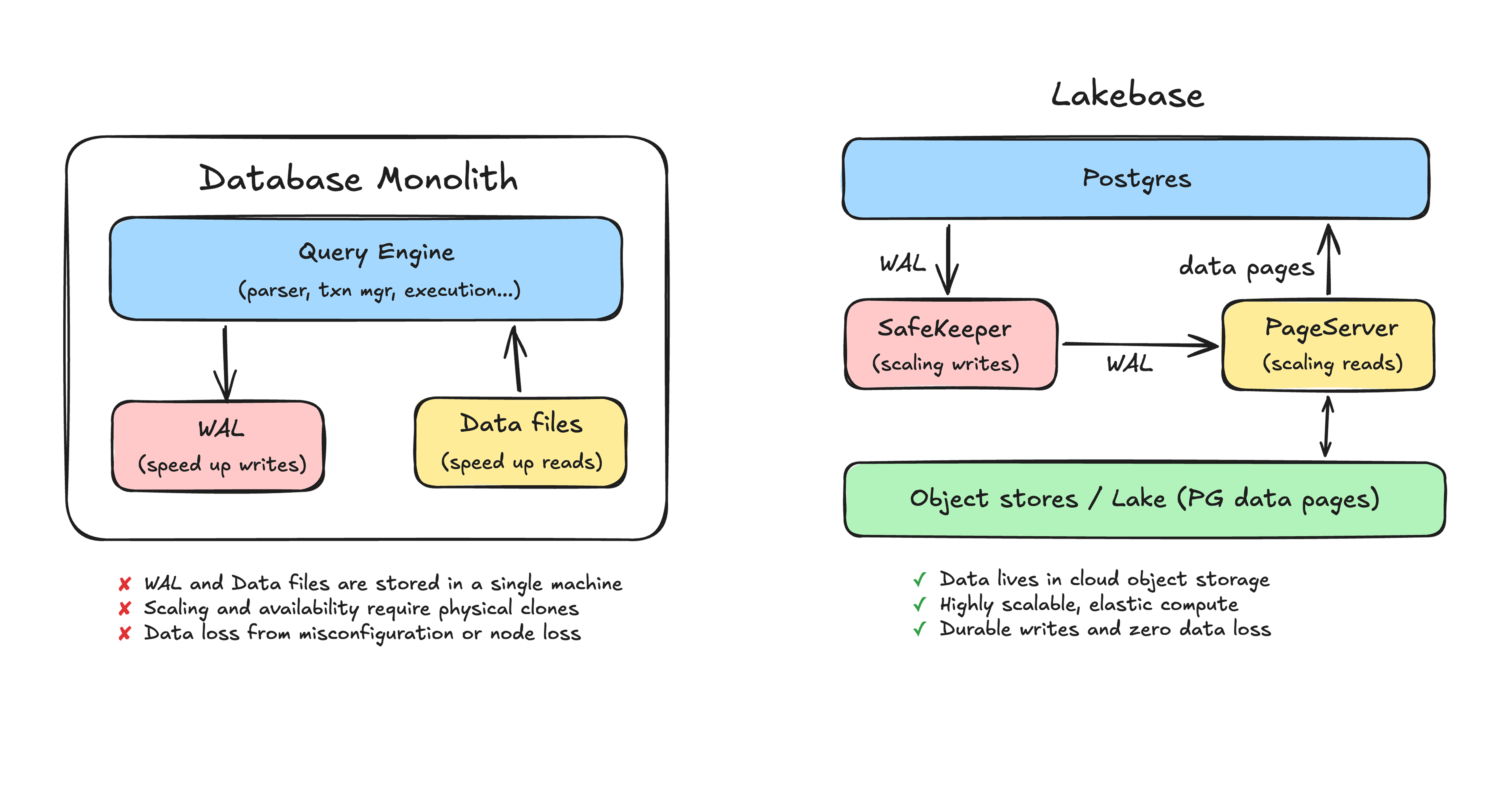
For years, the standard architecture for relational databases has been a monolith. In a traditional PostgreSQL setup, the compute engine (the logic that processes your SQL) and the storage layer (where the data actually lives on disk) are tightly coupled. While this works beautifully for many applications, it creates significant friction when you need to scale horizontally or provide real-time insights into operational data.
Enter LTAP.
The LTAP architecture represents a fundamental shift in how we think about database storage. By decoupling the Write-Ahead Log (WAL) and the primary data files from the compute engine, organizations can move toward a distributed model that leverages cloud-native capabilities like S3 for persistence while maintaining high performance.
The Bottleneck of Monolithic Storage
In a standard PostgreSQL deployment, if you want to scale your read capacity, you typically have to add more replicas. If you need more storage, you are often bound by the physical limits of the machine or the specific volume attached to it.
The biggest pain point for data engineers in this model is "data silos." When a business needs to run an analytical query on live production data, they usually can't do it directly against the primary database without risking performance degradation. This leads to the creation of complex ETL (Extract, Transform, Load) or CDC (Change Data Capture) pipelines. You end up with two copies of your data: one in a transactional database and another in a warehouse or lakehouse. Keeping these in sync is an engineering nightmare that introduces latency and potential for inconsistency.
How LTAP Changes the Equation
The "LTAP" model solves this by moving the storage layer to open, columnar formats—specifically Parquet—stored on object storage like Amazon S3 or Google Cloud Storage.
In this architecture:
- Storage is Independent: The data isn't trapped in a proprietary binary format that only one specific engine can read. Because it resides in Parquet files, any tool capable of reading Parquet (Spark, Presto, Databricks, etc.) can access the raw data.
- Compute is Elastic: Since the "source of truth" lives on S3, you can spin up multiple compute instances to handle different workloads—one for high-concurrency transactional queries and another for heavy analytical processing—all pointing at the same underlying files.
- Elimination of CDC Pipelines: Because both your operational database and your lakehouse tools are reading from the same Parquet files, you no longer need a complex "mirroring" system. The data is fresh by default because there is only one copy.
Practical Implementation: Moving Beyond Localhost
Moving to an LTAP architecture isn't just a theoretical shift; it requires a disciplined engineering approach. One of the most common mistakes I see in early-stage cloud migrations is testing with "toy" datasets.
If you are moving toward a decoupled storage model, your performance benchmarks must reflect reality. You cannot validate a distributed system using three rows on localhost. To truly understand the impact of LTAP, engineers must:
- Simulate Production Loads: Test against data volumes and query complexities that mirror actual production traffic to see how the system handles concurrency at scale.
- Measure p95 Latency: Averages are a dangerous metric in user-facing applications. While your "average" response time might look great, outliers (the 95th percentile) can ruin the experience for thousands of users. You must measure these tails to ensure the transition from local disk to S3 doesn't introduce jitter.
- Version Control Everything: As you experiment with different storage configurations and cache keys, use unique deployment IDs and experiment tags. This ensures that when a performance dip occurs, you can pinpoint exactly which configuration change caused it.
The Strategic Trade-off: Complexity vs. Scalability
Is LTAP the right choice for every project? Not necessarily. You are trading a simpler, single-machine architecture for a more complex distributed system.
In a traditional setup, debugging is often straightforward because everything happens on one box. In an LTAP model, you have to manage network overhead between compute and storage, handle eventual consistency nuances of object stores (though modern systems mitigate this), and manage the orchestration of multiple engines.
However, for organizations operating at "cloud scale," the trade-off is almost always worth it. The ability to eliminate redundant data pipelines and provide a unified view of truth across both operational and analytical workloads provides a massive competitive advantage in speed-to-insight. You move from managing "data movement" problems to solving "business logic" problems.
If you are looking to architect a scalable, modern data stack but aren't sure where the first brick should be laid, I can help you navigate these architectural trade-offs and build an MVP that scales. Contact me for expert guidance on your next project.
Summary of Key Takeaways
- Decoupling is the goal: Separate compute from storage to enable independent scaling.
- Open formats are key: Using Parquet allows multiple engines to read the same data simultaneously.
- No more mirrors: LTAP removes the need for complex CDC pipelines by creating a single source of truth on object storage.
- Rigorous testing: Success depends on measuring p95 latencies and using production-shaped loads during development.
Implementation help
Let's align on scope and next steps. Nitin Rachabathuni, Senior Full-Stack Engineer and MVP in 2 Days specialist — technical audits, implementation support, advisory, and flexible hourly collaboration shaped to your product. Reach out anytime; available across time zones and countries.
- Contact form
- Email: nitin.rachabathuni@gmail.com
- WhatsApp: +91-9642222836