The Architectural Shift: Moving Intelligence from Logic to Infrastructure
In the current landscape of Generative AI development, we have reached a point where application logic is becoming increasingly cluttered with orchestration overhead. Developers often find themselves building complex, nested agent graphs—loops, conditional branches, and state machines—directly within their backend code just to manage how different models interact.
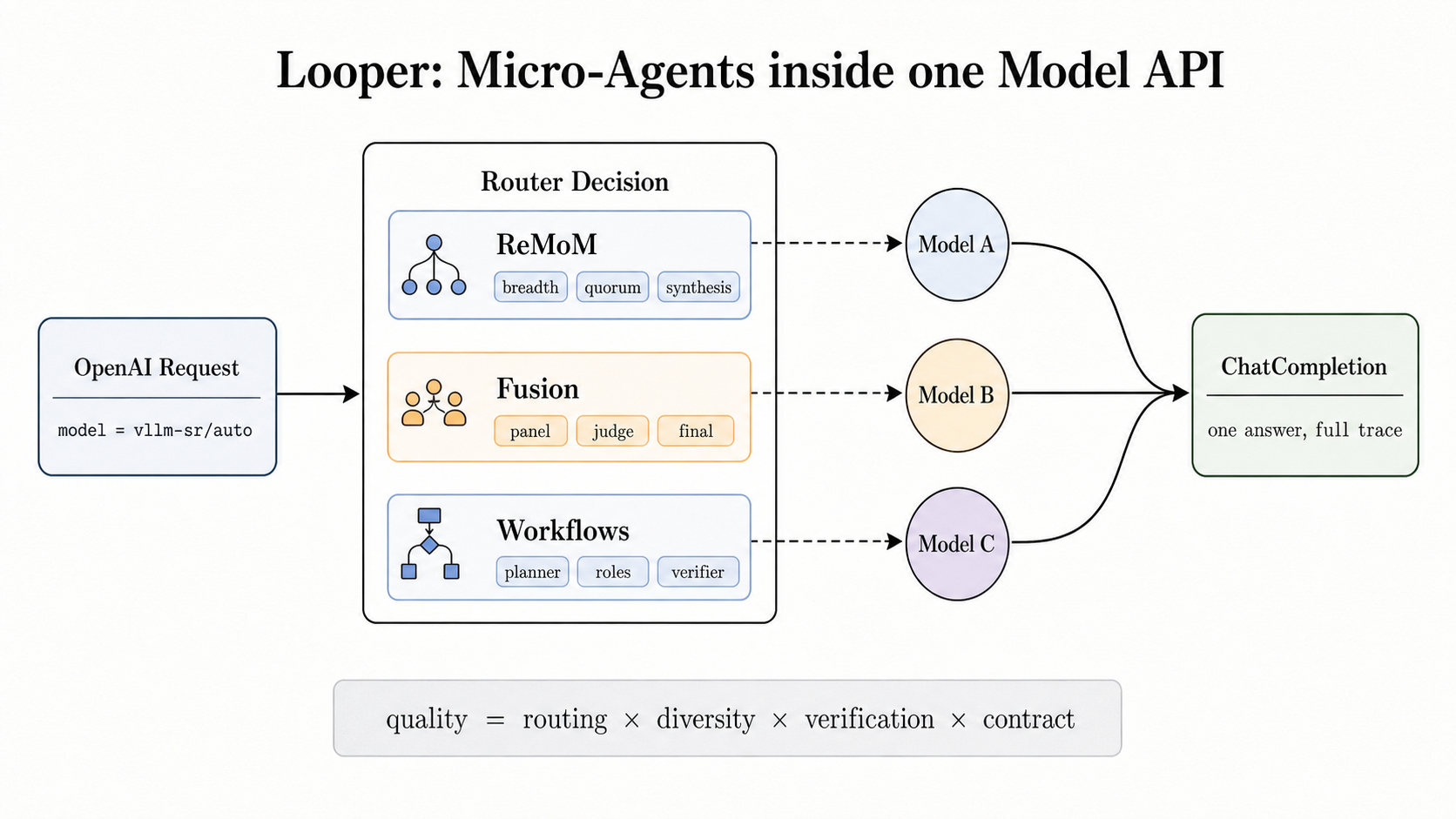
The "Micro-Agent" approach proposes a fundamental shift in this paradigm: move the collaboration into the serving layer.
Instead of your application logic managing three different API calls to three different models to complete one task, you treat the orchestration as an internal function of the model gateway or router. By doing this, you provide a single, clean API surface for your frontend while executing complex "micro-agent" collaborations behind the scenes. This is not just about cleaner code; it’s about moving complexity from the application layer to where it can be managed more effectively: the infrastructure level.
Why Serving-Layer Collaboration Wins in Production
When you build agentic workflows at the application level, your backend becomes a "manager" of LLM outputs. This introduces several friction points that scale poorly as your user base grows. By moving these capabilities into the serving layer (as seen in recent innovations like those discussed by vLLM), you gain three critical advantages:
1. Reduced Application Complexity
Your developers can focus on product features rather than debugging complex state machines for agentic loops. If a task requires specialized reasoning, it is handled as a "micro-agent" routine within the infrastructure. The application simply sends a request and receives a high-quality result.
2. Granular Cost Management
One of the biggest challenges in LLM production is cost control. When you use one massive frontier model for every task, your margins shrink. By using micro-agents at the serving layer, the router can intelligently route sub-tasks to smaller, cheaper models (like Llama or Mistral variants) while only calling a "frontier" model when high-level reasoning is strictly necessary.
3. Stricter Safety and Governance
By centralizing orchestration in the gateway/serving layer, you create a single point of enforcement for safety policies. Instead of having multiple different agents across your app with varying guardrails, the infrastructure provides a unified security perimeter where prompt injection checks and PII filtering can be enforced consistently before any model is touched.
The Trade-offs: Infrastructure Complexity vs. Application Simplicity
As an engineering leader, it is vital to recognize that this isn't "free" complexity—it’s shifted complexity. When you move logic into the serving layer, your infrastructure team takes on a larger role in defining how these micro-agents interact.
However, from a product lifecycle perspective, this trade-off is almost always favorable for scaling. A simplified application layer means faster deployment cycles and easier onboarding for new developers. The "heavy lifting" of choosing which model handles what part of the prompt happens once at the infrastructure level, rather than being reinvented in every microservice or frontend component.
To succeed with this architecture, you must move away from "gut feeling" routing. You need to benchmark your specific prompts and token mix against various models before setting them as defaults. Log every model ID and prompt version on every production call to ensure that when the infrastructure changes, you can trace exactly how it impacts the end-user experience.
Implementing a Robust Migration Strategy
If you are currently running complex agentic workflows in your application code, don't try to refactor everything overnight. Instead, adopt a phased approach:
- Identify "Hot" Workflows: Find the most frequent multi-step tasks that require multiple LLM calls.
- Isolate Sub-tasks: Break these down into discrete units of work (the micro-agents).
- Implement Canary Deployments: Before moving a core feature to the new infrastructure-led model, run it on low-risk endpoints. This allows you to validate that the "micro-agent" logic in the serving layer produces identical or superior results compared to your old application-level code.
By treating the router as an intelligent coordinator rather than a simple pass-through, you create a more resilient and cost-effective AI stack.
If you are looking to move from prototype to production and need help architecting a scalable LLM infrastructure that balances performance with operational overhead, contact me for MVP consulting to streamline your engineering roadmap.
Conclusion: The Path Forward
The era of "app-heavy" agent logic is giving way to "infrastructure-aware" AI systems. By embracing micro-agents within the serving layer, you can achieve frontier-level performance while maintaining a clean, manageable codebase. It’s about building for scale by moving complexity where it belongs—in the foundation of your stack.
Implementation help
Let's align on scope and next steps. Nitin Rachabathuni, Senior Full-Stack Engineer and MVP in 2 Days specialist — technical audits, implementation support, advisory, and flexible hourly collaboration shaped to your product. Reach out anytime; available across time zones and countries.
- Contact form
- Email: nitin.rachabathuni@gmail.com
- WhatsApp: +91-9642222836

