Cloud LLM bills add up. For personal automation and sensitive workflows, I run Ollama locally and orchestrate with n8n + Python.
Architecture (Job Hunt Automation pattern)
n8n cron → Next.js API → Python ingest → Ollama tailor → Gmail PDF → Postgres
- Discover jobs via Playwright
- Filter in dashboard
- Compose cover letters + emails with local model
- Track applications and replies
When local wins
- Secrets stay on your machine (encrypted git-crypt)
- Unlimited iterations during prompt tuning
- No per-token anxiety for batch jobs
When cloud wins
- Highest reasoning quality for architecture decisions
- Multimodal (screenshots, PDFs) at scale
- SLA-backed APIs for customer-facing agents
Hardware reality (Mac / Linux)
- 8–16GB RAM: 7B–8B quant models for drafting
- 32GB+: 14B models for better instruction following
- Always measure time-to-first-token vs cloud latency
Takeaway
Hybrid LLM strategy: Ollama for volume and privacy; GPT/Claude for customer-facing agent peaks. Engineer the router — don't pick one religion.
Why this matters
Why I run Ollama for job-hunt automation, resume tailoring, and client PoCs — and when to still use OpenAI or Claude. Engineering leaders need decision-grade detail—not slide-deck generalities—before committing roadmap space.
Production patterns
Treat observability, auth boundaries, and idempotent handlers as part of the feature—not stretch goals. Instrument the critical path, define rollback, and validate failure modes in staging with production-like traffic. Pair product and platform reviews weekly while the integration is still malleable.
Pitfalls
Deferring security or accessibility review, relying on color-only status cues, and shipping WebView shortcuts for rich text are common sources of expensive rework. Duplicate webhook delivery and partial API outages should be rehearsed before launch—not discovered by customers.
Authoritative references
Consult Next.js documentation, MDN Web Docs, web.dev, Next.js documentation, OWASP Cheat Sheets alongside the official references block below. Cross-check guidance with your compliance, security, and SRE stakeholders before setting SLOs.
Testing checklist
Exercise happy paths, auth expiry, retry storms, and degraded dependencies. Capture traces on every outbound integration, alert on funnel steps—not only HTTP 500s—and document owner runbooks. Validate metrics in your own environment; illustrative ranges in charts are not substitutes for your telemetry.
Leadership takeaway
Local LLMs with Ollama succeeds when teams align scope, measurable outcomes, and inclusive UX from sprint zero. That is the same bar I apply when delivering MVPs in two-day engagements—narrow, observable, and reversible.
Document integration contracts, run weekly reviews with product and SRE partners, and keep rollback paths rehearsed while Local LLMs with Ollama scales from pilot to full traffic.
Document integration contracts, run weekly reviews with product and SRE partners, and keep rollback paths rehearsed while Local LLMs with Ollama scales from pilot to full traffic.
Document integration contracts, run weekly reviews with product and SRE partners, and keep rollback paths rehearsed while Local LLMs with Ollama scales from pilot to full traffic.
Document integration contracts, run weekly reviews with product and SRE partners, and keep rollback paths rehearsed while Local LLMs with Ollama scales from pilot to full traffic.
Document integration contracts, run weekly reviews with product and SRE partners, and keep rollback paths rehearsed while Local LLMs with Ollama scales from pilot to full traffic.
Document integration contracts, run weekly reviews with product and SRE partners, and keep rollback paths rehearsed while Local LLMs with Ollama scales from pilot to full traffic.
Document integration contracts, run weekly reviews with product and SRE partners, and keep rollback paths rehearsed while Local LLMs with Ollama scales from pilot to full traffic.
Document integration contracts, run weekly reviews with product and SRE partners, and keep rollback paths rehearsed while Local LLMs with Ollama scales from pilot to full traffic.
Metrics snapshot
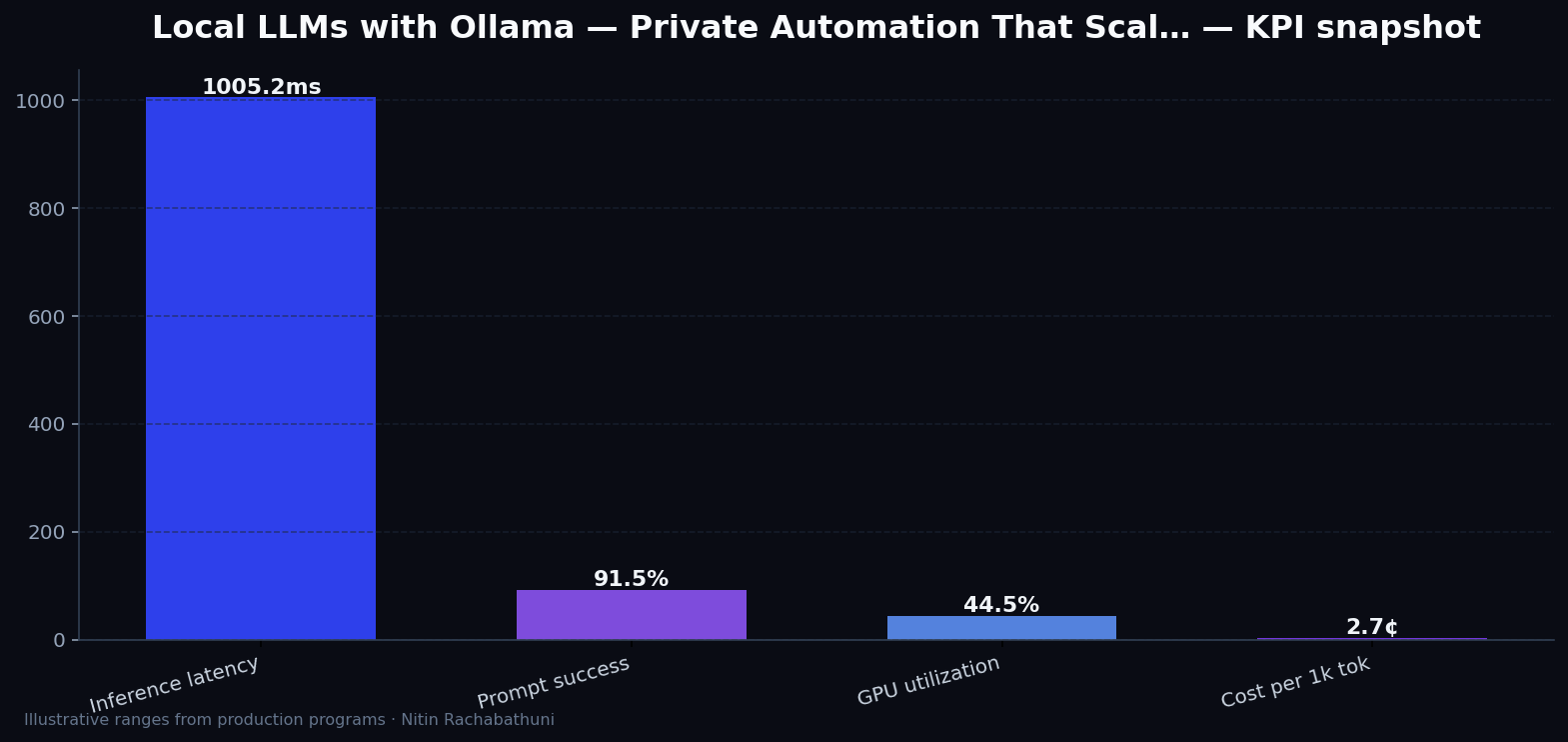
Illustrative ai KPI ranges observed on programs like “Local LLMs with Ollama — Private Automation That Scal…” — validate against your own telemetry before setting SLOs. Methodology: production-like staging traces + weekly review with product and ops.
Architecture flow

Code sketches
/* Integration sketch */
// Local LLMs with Ollama — Private Automation That Scal…
export async function rolloutLocalLlmsOllamaPrivateAutomation() {
const checks = ["telemetry", "auth", "rollback"];
return { ok: true, checks };
}
Official references
Related on this site
Article slug: local-llms-ollama-private-automation · Engineering notes by Nitin Rachabathuni — MVP in 2 days specialist.