The development era shifted from chat UIs to agentic systems that call tools, read repos, and execute workflows. Here's the stack I actually ship with in 2026.
LLM landscape (what I use and why)
| Model family | Best for | Production notes |
|---|---|---|
| GPT-4o / o-series | General reasoning, multimodal | Strong tool calling; watch token cost at scale |
| Claude (Anthropic) | Long context, careful codegen | Excellent for refactors and spec adherence |
| Gemini | Google ecosystem integrations | Good when GCP-native |
| Llama / Qwen (via Ollama) | Local-first, privacy, job automation | Zero cloud bill; tune prompts per hardware |
| Open-weight (HF) | Fine-tune & domain agents | Pair with LangGraph for guardrails |
No single winner — I route by latency, cost, privacy, and tool compatibility.
Model Context Protocol (MCP)
MCP standardizes how agents connect to databases, APIs, and IDEs. Instead of bespoke integrations per tool, you expose resources + tools once. This is why Cursor, Claude Desktop, and platform teams are converging on MCP servers for:
- Postgres / commerce APIs
- GitHub PR workflows
- Internal admin panels
Agent patterns that survive production
- Graphs over chains — LangGraph state machines with explicit human gates
- Tool allowlists — never give agents open network access
- Observability — log every tool call with correlation IDs
- Fallback paths — keyword routers when LLM confidence is low (social commerce order lookups do this well)
AEO / GEO / llms.txt
Discovery is no longer только Google. Answer engines (Perplexity, ChatGPT browse) and llms.txt files help models cite you accurately. I ship structured data + machine-readable profiles on every client site now.
Takeaway
Treat LLMs as orchestration layers, not magic. The engineers who win in 2026 pair models with MCP, graphs, and boring reliability engineering.
Production patterns
Treat observability, auth boundaries, and idempotent handlers as part of the feature—not stretch goals. Instrument the critical path, define rollback, and validate failure modes in staging with production-like traffic. Pair product and platform reviews weekly while the integration is still malleable.
Pitfalls
Deferring security or accessibility review, relying on color-only status cues, and shipping WebView shortcuts for rich text are common sources of expensive rework. Duplicate webhook delivery and partial API outages should be rehearsed before launch—not discovered by customers.
Authoritative references
Consult LangGraph.js, MDN Web Docs, web.dev, Next.js documentation, OWASP Cheat Sheets alongside the official references block below. Cross-check guidance with your compliance, security, and SRE stakeholders before setting SLOs.
Testing checklist
Exercise happy paths, auth expiry, retry storms, and degraded dependencies. Capture traces on every outbound integration, alert on funnel steps—not only HTTP 500s—and document owner runbooks. Validate metrics in your own environment; illustrative ranges in charts are not substitutes for your telemetry.
Leadership takeaway
LLMs, MCP, and the Agentic Web in 2026 succeeds when teams align scope, measurable outcomes, and inclusive UX from sprint zero. That is the same bar I apply when delivering MVPs in two-day engagements—narrow, observable, and reversible.
Document integration contracts, run weekly reviews with product and SRE partners, and keep rollback paths rehearsed while LLMs, MCP, and the Agentic Web in 2026 scales from pilot to full traffic.
Document integration contracts, run weekly reviews with product and SRE partners, and keep rollback paths rehearsed while LLMs, MCP, and the Agentic Web in 2026 scales from pilot to full traffic.
Document integration contracts, run weekly reviews with product and SRE partners, and keep rollback paths rehearsed while LLMs, MCP, and the Agentic Web in 2026 scales from pilot to full traffic.
Metrics snapshot
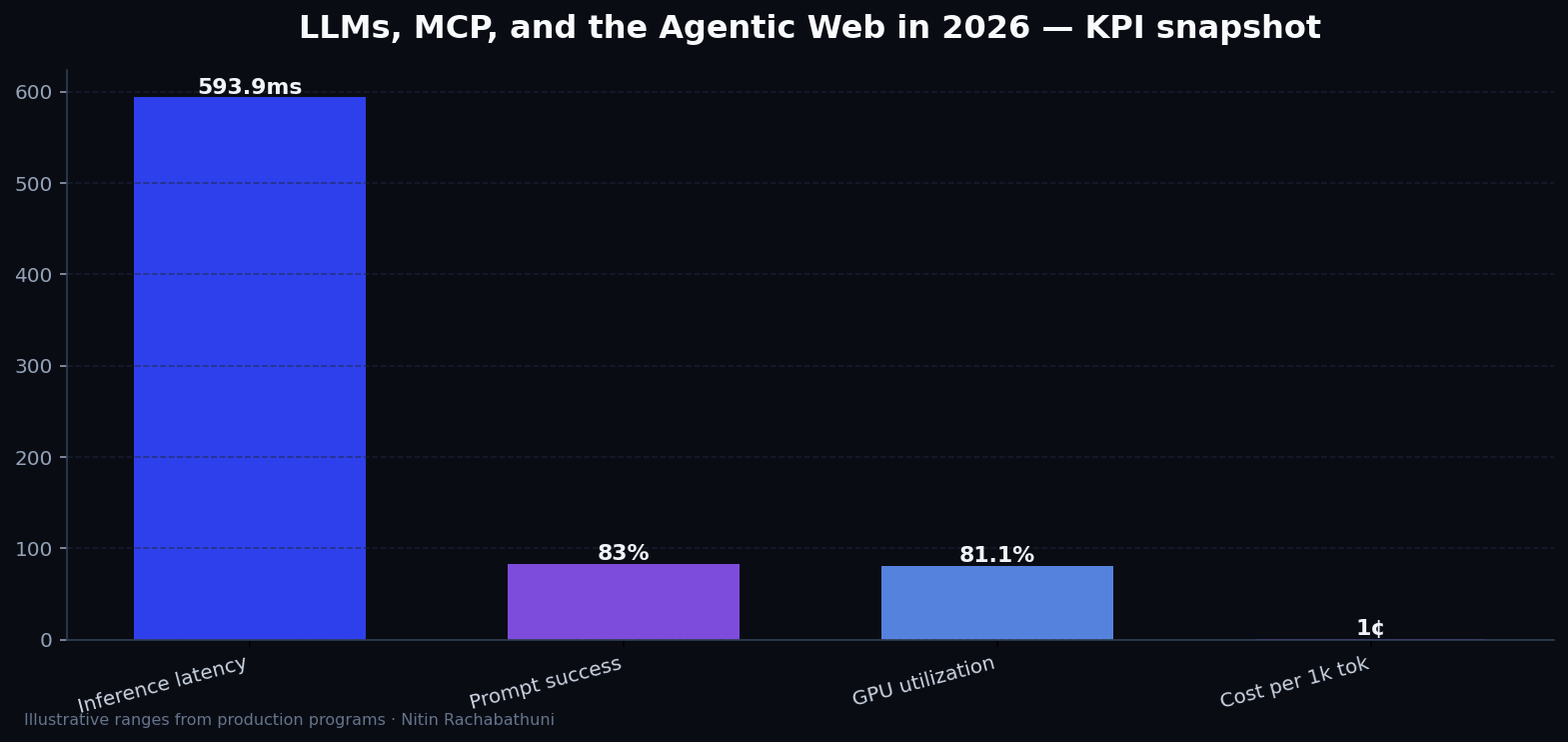
Illustrative ai KPI ranges observed on programs like “LLMs, MCP, and the Agentic Web in 2026” — validate against your own telemetry before setting SLOs. Methodology: production-like staging traces + weekly review with product and ops.
Architecture flow

Code sketches
/* Integration sketch */
// LLMs, MCP, and the Agentic Web in 2026
export async function rolloutLlmsMcpAndTheAgenticWeb2026() {
const checks = ["telemetry", "auth", "rollback"];
return { ok: true, checks };
}
Official references
Related on this site
Related case study
Juiceit.ai — AI platform — document intelligence, agent workflows, enterprise automation.
Article slug: llms-mcp-and-the-agentic-web-2026 · Engineering notes by Nitin Rachabathuni — MVP in 2 days specialist.

Juiceit style straight through document processing
AI Agents
Why Claude Code Switching to a Rust-based Bun Runtime Matters for AI Engineering
tech
Why Anthropic's Move to a Rust-Based Bun Runtime for Claude Code Matters for Engineering Leaders
leadership
Architecting Safety: Why a Dedicated Machine is Essential for Claude Code Agentic Workflows
leadership

LM Studio Bionic: Bridging the Gap Between Chatting and Agentic Workflows
tech

The Zero-Cost Fallacy: Navigating Open Source Risks in the Agentic Era
leadership